James Tauber's Blog 2007
blog >
The Future Comes in Green and White
This week I received two significant packages: my "spit kit" to provide a DNA sample for 23andMe to analyze and my One Laptop Per Child XO-1.


I think both of these are landmarks. I'll report on both over the coming months.
Here are some more photos:
by : Created on Dec. 21, 2007 : Last modified Dec. 21, 2007 : (permalink)
You Me Us We Named Top Song of 2007
Back in May, I wrote about the song You Me Us We which was originally an instrumental piano piece of mine to which Nelson Clemente later added vocals as part of our Nelson James collaboration. For Nelson's solo debut EP, I worked with producer Rob Agostini on an electropop version that was described by one reviewer as "the perfect blend of sparkly pop that will make you feel like the world isn't so bad after all".
The site ElectroQueer has always been a fan of the song but they just released their Top 120 Songs of 2007 and guess which song ended up at #1!
Thank you Nelson and Rob and ElectroQueer for making a simple piano piece I wrote as a 19-year-old into an international number one pop song!
by : Created on Dec. 21, 2007 : Last modified Dec. 21, 2007 : (permalink)
Quisition Hits 1000 Users
Yesterday, Quisition had it's 1,000th user registration, which was my target for this year. Admittedly, this was fairly easy to control because most of the new users come via Google Adwords and I could adjust the budget to keep things on track to hit 1,000 before year end.
Comparing the figures from the first 100 users:
- Only 71% activated their account (down from 89% in the first 100)
- Only 58% created a deck for testing (down from 72% in the first 100)
- Only 37% actually learnt any cards (down from 57% in the first 100)
I have a bunch of feature requests from regular users of the site and implementing those will now be my top priority. But I also want to explore why the percentages above are so low. I'm not surprised they are lower than those for the first 100 given most of the traffic now comes from Adwords rather than this blog. But it should be possible to get them higher than they currently are.
by : Created on Dec. 20, 2007 : Last modified Dec. 20, 2007 : (permalink)
Avoiding Recursion
Occasionally I implement an algorithm recursively then hit the recursion limit in Python.
For example, I just wrote this:
def clique(self, node, done=None): if done is None: done = set() done.add(node) for other_node in self.edges_by_node[node]: if other_node not in done: self.clique(other_node, done) return done
which hits a limit if the graph is too big.
So I rewrote it like this:
def clique(self, start_node):
done = set()
to_do = [start_node]
while to_do:
node = to_do.pop()
done.add(node)
for other_node in self.edges_by_node[node]:
if other_node not in done:
to_do.append(other_node)
return done
There's a simple relationship between the two, quite independent of the specific task at hand. Which got me thinking about abstracting the specific task out of the recursive versus non-recursive pattern.
I guess I was having an SICP moment :-)
by : Created on Dec. 15, 2007 : Last modified Dec. 15, 2007 : (permalink)
Resizable Text Areas
Is it just me or are Safari 3's resizable text areas really really cool!
by : Created on Dec. 15, 2007 : Last modified Dec. 15, 2007 : (permalink)
Stack-Type Vectors, Part III
Part of the Poincaré Project.
We've already been introduced to linear spaces and three different types of linear space: n-tuples, arrow-type vectors and stack-type vectors.
In the last post, I promised to motivate stack-type vectors from the perspective of physics.
Both arrow-type vectors and stack-type vectors (in contrast to plain n-tuples) exist in relation to a manifold. From the point of view of (at least pre-relativistic) physics, the manifold introduces a notion of position and distance, but not other quantities such as time or mass or electrical charge, which exist in addition to the structure of the manifold.
We've previously stated that displacement, velocity, acceleration, force, etc can all be modeled as arrow-type vectors. The reason is that they are all fundamentally about a change in position. If you do a dimensional analysis—L, LT-1, LT-2, MLT-2—you see that they all have a single length dimension: no length squared; no per unit length.
Arrow-type vectors can't be used for area, energy or power (all of which have L2). Nor can they be used for quantities that are measured per unit area (L-2) or per unit volume (L-3 e.g. density which is ML-3).
Finally, arrow-type vectors cannot be used for quantities that are measured per unit length (L-1) but this is where stack-type vectors come in.
Borrowing the example from Gabriel Weinreich's wonderful book, Geometrical Vectors (the first book to set me straight on this stuff), consider two plates 1cm apart with a potential difference of 30V. We can model the distance between the plates as an arrow-type vector d. The electric field E between the plates is 30V/cm. E is not an arrow-type vector, but a stack-type vector.
One way to see this is the different behaviour of the numerical values of d and E under a change of scale. If we change our measurements from centimetres to metres, the numerical value of d goes from 1 to 0.01 but the numerical value of E goes from 30 to 3000.
This difference can also been seen in the fact that, when stretched, the magnitude of an arrow-type vector increases whereas the magnitude of a stack-type vector decreases.
Arrow-type vectors are about position and rates of change of position. Stack-type vectors, on the other hand, are about rates of change of some other quantity as position changes.
If you are familiar with gradient vectors from vector calculus, it should start to become clear that gradient vectors are not of the arrow-type but rather the stack-type.
In conclusion, while arrow-type vectors and stack-type vectors both follow the axioms for linear spaces, their behaviour in relation to the manifold they get their geometric interpretation from differs. It could almost be said they are opposites. Notice that while the numerical value of d decreased and that of E increased in our scaling example, if you multiple them together, they stay constant.
Exploring this last observation will be topic of the next post in the series.
by : Created on Dec. 15, 2007 : Last modified Dec. 15, 2007 : (permalink)
New Quisition Features
A couple of people requested a while ago the ability to delete decks of cards from my flashcard site, Quisition. This evening I finally got around to implementing that feature. I also got an email yesterday asking for the ability to export cards, so I implemented that while I was at it.
I still have a huge long list of things to implement in Quisition including OpenID, comments and tagging of packs, user rankings, email reminders and lots more.
I'm still on track to hit 1,000 users by the end of the year. Very few of those use the site regularly, though, so one of the things I want to do early next year is survey the users to find out what I need to improve to keep them coming back.
by : Created on Dec. 14, 2007 : Last modified Dec. 14, 2007 : (permalink)
Numerical Representation of Pitch
A number of years ago, I started working on a Python library for music theory and composition called Sebastian and one of the first implementation decisions I needed to make was how to represent pitch. Assuming one allows for double-flats and double-sharps, there are 35 note names. What I was looking for was a way to represent these 35 note names in a way that was consistent with the relationships between them.
I ended up deciding to use the set of integers with D as 0 and each successor being a 5th higher. So A would be +1, E +2, G -1, Eb -5, F# +4 and so on.
This turns out to work quite nicely. Given one note, you can find the tone above/below by adding/subtracting 2 and the semitone (different letter) above/below by subtracting/adding 5. To augment/diminish (same letter) you can add/subtract 7.
You can determine if two notes are enharmonic by testing
(abs(val1 - val2) % 12) == 0
You generate the textual note name from this integer with:
modifiers = ((val + 3) - ((val + 3) % 7)) / 7 if modifiers == 0: m_name = "" elif modifiers == 1: m_name = "#" elif modifiers > 1: m_name = "x" * (modifiers - 1) else: # m < 0 m_name = "b" * -modifiers return "DAEBFCG"[val % 7] + m_name
and the reverse with
letter = name[0] base = "FCGDAEB".find(letter) - 3 if base == -4: raise ValueError mod = name[1:] if mod == "": m = 0 elif mod == "#": m = 1 elif mod == "x" * len(mod): m = len(mod) + 1 elif mod == "b" * len(mod): m = -len(mod) else: raise ValueError return base + m * 7
While it's true that moving the origin to F would eliminate some of those -3s and +3s, new ones would need to be introduced, so there's no really clear winner between an origin at D versus an origin at F.
Scales are easy to generate. The pattern for a major scale is [0, 2, 4, -1, 1, 3, 5] and so you can generate the scale for a particular tonic with something like
[tonic + i for i in [0, 2, 4, -1, 1, 3, 5]]
Another advantage of the system is it can be extended to 19-et and other tuning systems. I haven't given much thought to whether it's useful for tunings without a constant frequency ratio for the 5th, though.
I also haven't yet investigated how this system is inferior to Hewlett's base-40 system.
UPDATE: Okay, I've finally grokked the functional difference between Hewlett's system and mine. Mine can incorporate an infinite number of note names (triple flats, quadruple sharps, you name it) but it cannot express intervals of an octave or more. Hewlett's base-40 system can handle intervals of octaves or above but cannot, without change, handle more than the 35 note names of 12-tone chromatic music. My system (and others like it) require two numbers to handle more than an octave. Hewlett traded off infinite note-naming capability for the ability to include octave in a single number.
by : Created on Dec. 13, 2007 : Last modified Dec. 14, 2007 : (permalink)
Man from Earth
Earlier this week, I read Graham Glass's description of the movie ''Jerome Bixby's Man from Earth'':
The Man from Earth looks like my kind of movie. It's shot entirely in a living room and revolves around a man who reveals to his colleagues that he has lived on Earth for the past 14,000 years. The rest of the movie is about how his colleagues try and disprove his confession via a question and answer session.
Well, it sounded like my kind of movie too so I ordered and, on Wednesday evening, it arrived.
It's a fascinating concept and, for the most part (see below), dealt with very well. It was written by the late Jerome Bixby, of original series Star Trek writing fame.
It was obvious early on that it wasn't shot on film—a lot of low-light noise, even more noticeable than Attack of the Clones, make it clear this was shot on video. IMDb says it was shot on prosumer-grade HDV, possibly an HVX200 judging by the single behind-the-scenes shot of the camera I saw on the film's website. But this was way better done than most films shot on video. Given that it was shot on video and all in one location, it must have been an amazingly cheap film to make.
The acting was generally good. The performances sometimes felt more like a play than a film (and I mean that as a negative—stage acting looks like over-acting on camera) and I wonder how much of that is because it was shot all in one location and probably only over a few days. The story would actually lend itself to a stage performance given that it is all in one location and entirely dialogue-driven.
The pacing was excellent. There was only one time where I started to lose interest and almost immediately, the drama of it picked up and I was hooked again.
I really don't want to say much about the content itself as it's fun just going on the journey. I will, however, raise one complaint.
The film presents a very controversial portrait of Christian origins, which in-and-of-itself doesn't bother me. What disappointed me, however, was that it was done in such a simplistic and naïve way. With just a little more homework, Bixby could have made it a tighter (and no less controversial) argument.
For example, he confuses the uncertainty of certain words of Jesus with the existence of multiple English translations, seemingly ignorant of the fact that the Greek underlying the translations is known and so the uncertainty has nothing to do with the English language translations. He could have expressed the uncertainty in a far more informed way by appealing even just to differences between the Synoptic Gospels let alone issues of textual and higher criticism.
I don't know enough archaeology, paleogeography or biological anthropology to know whether there were glaring errors in those areas, but I suspect not nearly as blatant.
It's a shame because, otherwise it's a nicely done film. I would recommend it to any fans of thought-provoking high concept science fiction. I didn't love it quite as much as Primer (although it's better acted) but it's up there. Certainly if you liked one, you'll like the other.
by : Created on Dec. 7, 2007 : Last modified Dec. 7, 2007 : (permalink)
Dwarves vs Dwarfs
I've long known that Tolkien favoured dwarves to dwarfs as the plural of dwarf but, living post-Tolkien, it's easy to forget that dwarfs was ever the preferred spelling. Then it was pointed out that the Disney film (which came out the same year as The Hobbit) is Snow White and the Seven Dwarfs. I don't think I ever noticed that before.
It was pointed out by Aardy R. DeVarque's Sources of D&D page which is an interesting study of the origins of many terms in the original D&D (hint: they weren't all from Tolkien!)
UPDATE (2007-12-09): Mark Liberman talked about /-fs/ vs /-vz/ plurals back in 2004 in The Theology of Phonology with a followup specifically on Dwarves vs Dwarfs.
by : Created on Dec. 5, 2007 : Last modified Dec. 9, 2007 : (permalink)
Rubik's Cube
Like many people (I'd guess most people reading this blog), I had a Rubik's Cube in the 80s.
The only way I could solve it was looking up moves in the book You Can Do The Cube by Patrick Bossert. (Patrick was only 12 when he wrote the book—he's now an entrepreneur and management consultant; see his home page).
In high school I had Rubik's Magic which I took detailed notes on and came up with a solution on my own. Later I came across a book with a much shorter solution that I seem to recall memorizing in the bookstore without buying the book.
Also in high school, I had Rubik's Clock which was also easy enough to solve on my own.
Then last year, when I was in Walt Disney World surprising my sister for her 21st, I bought a Rubik's Cube again with the goal of learning how to solve it.
Wikibooks has a nice page on How to solve the Rubik's Cube that has a straightforward algorithm as well as a discussion of various other approaches favoured by speedcubers.
Wikipedia also has a very interesting article on Optimal solutions for Rubik's Cube. It was only August this year that Kunkle and Cooperman proved Twenty-Six Moves Suffice for Rubik’s Cube (pdf of paper).
UPDATE (2008-03-27): Now see Twenty-Five Moves Suffice
by : Created on Nov. 26, 2007 : Last modified March 27, 2008 : (permalink)
Leopard After Two Weeks
Feature I use a lot that I didn't think I would: Quick Look
Feature I don't use as much as I thought I would: Spaces
Performance improvement that blew me away: Spotlight (it's amazing!)
UI changes that don't bother me: reflecting dock with glowing orbs and translucent menu bar
UI changes that do bother me: menu selection colour (too blue) and non-focused tabs in Safari (the combination of the embossing on the dark grey is horrible)
by : Created on Nov. 19, 2007 : Last modified Nov. 19, 2007 : (permalink)
Automatic Categorization of Blog Entries
I just went through a couple of years of posts, tagging some of those written before I introduced categories to Leonardo (in particular, the ones about Alibi Phone Network). It occurred to me that this categorization could be a job for machine learning.
I've talked before about using techniques like Bayesian Classification for identifying posts in an aggregator that one might be more likely to be interested in. But it didn't occur to me until now that similar techniques could be used to suggest which existing categories to place uncategorized entries into.
At some stage in the near future, I'll try a quick implementation in Leonardo and see how it goes.
by : Created on Nov. 18, 2007 : Last modified Nov. 18, 2007 : (permalink)
The Death Of Email
So Slate has an article entitled The Death of E-Mail about the younger generation in the US abandoning email. My colleague and good friend Jim Hickey made the same observation to me month or two ago. For his sons, email is how you submit papers to your teachers. It's a formal means of communication, much like snail mail is to me.
Actually, Facebook messaging is replacing email even for me for a certain class of communication. And just in the last 24 hours I've received a number of messages (about my MINI purchase) from old friends I haven't seen in years (more than 20 years in one case) who I wouldn't even be in touch with at all if it wasn't for things like Facebook. Even between me and my colleagues, non-work communication is done more over Facebook than email now.
by : Created on Nov. 18, 2007 : Last modified Nov. 18, 2007 : (permalink)
Back To The Feature
Way back in February 2006 I blogged about starting my first feature film. Tom had just completed a first draft and I had some tough criticism that led to a number of big rewrites. Today, Tom delivered a draft (see his blog entry about it) that will form the basis of the initial script breakdown, production planning and budgeting.
21 months seems like a long time to get a script to this stage but I would hazard a guess that it's actually fairly quick by Hollywood standards. For a low-budget indie, we've probably done a lot more script revisions than the norm but I hope that shows in the quality of the final film.
So the next step is a script breakdown. That's where I take Tom's script and basically construct a database of all the characters, locations, props, special equipment, etc required. This will give me a much better idea of how long the film will take to make and how much it will cost to make.
I'm hoping to have something done by the end of next weekend.
by : Created on Nov. 18, 2007 : Last modified Nov. 18, 2007 : (permalink)
My New MINI
Today I picked up my new car: a dark silver MINI Cooper S with the Premium, Sports and Cold-Weather packs. I've honestly never enjoyed driving so much in my life.
After much deliberation I got a 6-speed manual. I was worried about having to shift with my right hand (while I've driven manual in Australia, I've never driven stick in the US). But I'm so glad I went with it. No problem at all switching hands (I guess the real work is in the feet anyway and they don't switch).
I can't push it too hard for the first 1,200 miles but the acceleration in second gear is awesome.
The interior controls are really nicely done but I'm going to need to sit down with the manual to really get a hang of everything (trip computer, iPod integration, etc)
The purchasing experience at MINI of Peabody was excellent. You are really made to feel like you are joining the "cool club". Maybe MINI is the Apple of cars.
I love it! And I'm not into cars at all :-)
by : Created on Nov. 16, 2007 : Last modified Nov. 18, 2007 : (permalink)
NaNoBloMo and Memphis
Hmm, between being sick and traveling to Memphis on business, I'm not doing a very good job at NaNoBloMo.
I have a backlog of blog posts to write, though, so I might still make 30 posts this month, although likely not the 50 I'd hoped.
At Memphis airport they promote the city in three ways: "Home of the Blues", "Birthplace of Rock'n'Roll" and "America's Distribution Center". More air cargo goes through Memphis than any other airport in the world. I think I saw more FedEx planes at the airport than passengers.
Being sick, though, I didn't get to see anything of Memphis. No Graceland tours or anything. Although it did occur to me as I took NyQuil LiquiCaps one night that popping pills might have been an authentic Elvis experience.
by : Created on Nov. 16, 2007 : Last modified Nov. 16, 2007 : (permalink)
I Wish NBC Shows Were On iTunes Again
I wish NBC would sell their shows on iTunes again. Watching Heroes on nbc.com is horrible.
by : Created on Nov. 11, 2007 : Last modified Nov. 11, 2007 : (permalink)
Distance and Checksum Algorithms on Lists
Related to the programming competition, I've started thinking about algorithms for:
- measuring the distance between two orderings of the same list (I guess number of swaps required to go from one to the other; even better if the algorithm gave you the swaps required)
- order-sensitive checksums on lists of integers (as above, the lists always contain the same elements but the goal is to have a checksum that distinguishes different orderings with minimal clashes)
Any suggestions for approaches to these? Working Python code would be even better :-)
by : Created on Nov. 10, 2007 : Last modified Nov. 10, 2007 : (permalink)
Genius
I've mentioned before that Malcolm Gladwell is a wonderful speaker. Since then I've also come across his TED talk. His talks have really taught me the power of story telling (something I confess I never did during all my XML and Web Services talks from 1997-2001 :-).
Via Kottke I found a wonderful video about the notion of genius. It's material from Gladwell's forthcoming book (talked about in Kottke's post).
Watch the video. I'm really looking forward to the book.
by : Created on Nov. 9, 2007 : Last modified Nov. 9, 2007 : (permalink)
False Initials
People often assume that ISO stands for "International Standards Organization". But in English the full name of the organization is "International Organization for Standardization". Oh, it must be the initials of the French name, some clever people suggest. But the French name is "Organisation internationale de normalisation".
ISO isn't an acronym or initialism at all: it's based on the prefix iso- derived from the Greek ἴσος "equal".
Another example of a non-initialism is UTC. In English, this atomic clock based version of GMT is "coordinated universal time". In French it's "temps universel coordonné". So why UTC? Well, it was just a compromise between CUT and TUC to keep both the English-speaking world and French-speaking world happy.
by : Created on Nov. 8, 2007 : Last modified Nov. 8, 2007 : (permalink)
Explaining Category Theory With Object-Oriented Programming
I recently came across Category Theory for the Java Programmer. At various points in the Poincaré Project, I've considered writing code to illustrate mathematical structures. Recently reading about category theory (and topoi in particular) I have myself been tempted to think of them in terms of OO programming.
My inclination would, of course, be to use Python, but static typing is probably more useful for explicitly showing the structure of mathematical objects (although at the end of the day, mathematics is about duck typing: if it follows the axioms of a linear space, it is a linear space).
So the post is pretty cool. But what I felt got in the way of using Java to explain category theory is that category theory is essentially about relationships between classes (in the OO sense—or least what OOA/OOD thinks of as what classes are supposed to map to in the real world). The objects in a category like Set are sets, not elements. The objects in a category like Vect are vector spaces, not vectors. Now one might argue that category theory doesn't really care about elements and vectors, only sets and vector spaces. So you could just shift your "metaness" one to the left. One might also argue (as the blog post referenced at the start does) that classes in Java are instances of the class Class so calling a class an object is allowed. But I think it just makes things confusing for the average OO programmer (especially if you think OO == Java).
A better language for illustrating category theory would be one that has a more explicit notion of a metaclass. Then it would be easier to explain category theory as essentially about different characteristics of metaclasses.
by : Created on Nov. 8, 2007 : Last modified Nov. 8, 2007 : (permalink)
Is Vocab Ordering Like Page Rank?
The basis for the vocab ordering project was the realization that even more valuable than learning a common word is learning a common word that shares a lot of sentences with a lot of other common words.
Imagine a network of "knowledge states" where arcs represent what you need to learn in order to move from one level of knowledge to another. It was the idea of finding a path through such a network that eventually led me to make the connection with the traveling salesman problem.
It just occurred to me this evening that there may be a connection with Google's Page Rank algorithm too. After all, it's all about finding the links to the pages judged most valuable because they have links to the most valuable pages and so on.
As the wikipedia article says: "the algorithm may be applied to any collection of entities with reciprocal quotations and references".
Incidentally, I was at the conference where the PageRank paper was first presented. It was WWW7 in 1998. I ran the XML tutorial and sat on a panel on hypertext. I can't remember if I attended the Brin/Page talk or not, though. I do remember hanging out with Ted Nelson (and having dinner with him and Roger Clarke) and meeting Rohit Khare and Adam Rifkin for the first time there.
by : Created on Nov. 6, 2007 : Last modified Nov. 6, 2007 : (permalink)
Zellyn Hunter Takes Lead
Zellyn Hunter has taken the lead in Category IV of my programming competition using simulated annealing.
Congratulations, Zellyn!
Meanwhile, my Category III local search is still running :-)
by : Created on Nov. 6, 2007 : Last modified Nov. 6, 2007 : (permalink)
Tabu Search
In a year old comment on a three year old post relating to vocabulary ordering using simulated annealing, Chris Huntley suggests tabu search might be a better approach.
Unfortunately, I only noticed the post now (sorry Chris). I hadn't come across tabu search before but started to do some investigation and wrote the beginnings of a Python implementation. My limited understanding so far is that you essentially do a local search amongst all possible swaps but keep a list of recent swaps that are "taboo" (hence the name) so you aren't always picking the local optimum.
I started off just writing a local search version (without the tabu) and found that on my programming competition, I could get the global optimum in Category I and a pretty good score for Category II (almost as good as I could get using SA). The problem is that the local search is damn slow.
Unlike the travelling salesman problem where a swap doesn't require full recalculation of the score, in my vocabulary ordering problem, I haven't yet worked out a way to avoid having to run the entire scorer for every swap. In local search, that's O(n2) in the number of verses (Category III hasn't finished running yet after 12 hours).
I need to work out a way of improving that before I finish implementing the rest of the tabu search.
I'm also thinking ant colony optimization might be another approach.
Of course, people with more experience in these algorithms than me are more than welcome to submit an entry in the programming competition using them.
by : Created on Nov. 5, 2007 : Last modified Nov. 5, 2007 : (permalink)
The Wolfram Prize
I've had on my "to blog about" list for months the Wolfram Prize to prove that a certain 2,3 Turning Machine is universal.
Well, in the mean time, Alex Smith has gone and won the prize. I'll still blog about the theory behind the prize, though, and maybe eventually say some things about the proof (pdf).
by : Created on Nov. 4, 2007 : Last modified Nov. 4, 2007 : (permalink)
GNT Verse Coverage Statistics
It is fairly common, in the context of learning vocabulary for a particular corpus like the Greek New Testament, to talk about what proportion of the text one could read if one learnt the top N words.
I even produced such a table for the GNT back in 1996—see New Testament Vocabulary Count Statistics (via Internet Archive's Wayback Machine).
But these sort of numbers are highly misleading because they don't tell you what proportion of sentences (or as a rough proxy in the GNT case: verses) you could read, only what proportion of words.
Reading theorists have suggested that you need to know 95% of the vocabulary of a sentence to comprehend it. So a more interesting list of statistics would be how many verses can one understand 95% of the vocab of if one know a certain number of words. Of course, there's a lot more to reading comprehension than knowing the vocab. But it was enough for me to decide to write some code yesterday afternoon to run against my MorphGNT database.
To first of all give you a flavour in the specific before moving to the final numbers, consider John 3.16, which is, from a vocabulary point of view, a very easy verse to read.
To be able to read 50% of it, you only need to know the top 28 lexemes in the GNT. To read 75% you only need the top 85 (up to κόσμος). With the top 204 lexemes, you can read 90% of the verse and only a few more: up to 236 (αἰώνιος) gives you the 95%. The only word you would not have come across learning the top 236 words would be μονογενής but even that is in the top 1,200.
This example does highlight some of the shortcomings of this sort of analysis. There's no consideration of necessary knowledge of morphology, syntax, idioms, etc. Nor for the fact that the meaning of something like μονογενής is fairly easy to guess from knowledge of more common words. But I still think it's much more useful than the pure word coverage statistics I linked to earlier.
So let's actually run the numbers on the complete GNT. If you know the top N words, how many verses could you understand 50% of, 75%, 90% or 95% of...
| vocab / coverage | any | 50% | 75% | 90% | 95% | 100% |
| 100 | 99.9% | 91.3% | 24.4% | 2.1% | 0.6% | 0.4% |
| 200 | 99.9% | 96.9% | 51.8% | 9.8% | 3.4% | 2.5% |
| 500 | 99.9% | 99.1% | 82.3% | 36.5% | 18.0% | 13.9% |
| 1,000 | 100.0% | 99.7% | 93.6% | 62.3% | 37.3% | 30.1% |
| 1,500 | 100.0% | 99.8% | 97.2% | 76.3% | 53.5% | 44.8% |
| 2,000 | 100.0% | 99.9% | 98.4% | 85.1% | 65.5% | 56.5% |
| 3,000 | 100.0% | 100.0% | 99.4% | 93.6% | 81.0% | 74.1% |
| 4,000 | 100.0% | 100.0% | 99.7% | 97.4% | 90.0% | 85.5% |
| 5,000 | 100.0% | 100.0% | 100.0% | 99.4% | 96.5% | 94.5% |
| all | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% | 100.0% |
What this means is purely from a vocabulary point of view if you knew the top 1000 lexemes, then 37.3% of verses in the GNT would be 95% familiar to you.
I should emphasis that learning vocabulary in frequency order isn't necessarily the fastest way to get this proportion of readable verses up. I blogged about this fact three years ago, see Programmed Vocabulary Learning as a Travelling Salesman Problem, for example.
by : Created on Nov. 4, 2007 : Last modified Nov. 4, 2007 : (permalink)
Initial Thoughts on Leopard
I've just finished installing Leopard on my laptop and so far, so good.
I started off doing a simple backup (copying folders to an external drive) and then did a full Erase and Install as I always like to do. Installation itself was a breeze.
After installation, the first thing the OS wants to do is build the Spotlight index. I made the mistake of having the external drive plugged in when this started and it was reporting it was going to take 2 hours to build the index. Fortunately, I realised what was going on and told Spotlight not to index the external drive (which it honoured immediately).
After Spotlight indexing, Leopard asked me if I wanted to use the external drive as the Time Machine drive. I said yes and it proceeded to basically make an entire copy of the initial Leopard install. For every snapshot Time Machine takes, a directory tree is created on the external drive. Files that haven't changed are hardlinks shared by previous versions. It's a pretty neat way of doing it—it basically means you can navigate to any snapshot and it looks like the full filesystem. The disadvantage of the hardlink approach is entire files are stored, not deltas, so if you change one byte in a 100MB file, the 100MB gets stored twice.
My Address Book and bookmarks didn't sync via .Mac as I'd hoped so, for the bookmarks, I found the .plist file in the backup and copied it over. The Address Book was a little more involved as it appears they changed the file format. Fortunately, I hadn't upgraded my MacPro yet so was able to copy from the backup to Tiger on my MacPro and export from there in a format that Leopard could read in.
Oddly enough, though, my Mail accounts did sync via .Mac so when I opened Mail.app, it started the lengthy process of downloading 2GB of mail over IMAP. The left pane is ordered differently (my non-Inbox IMAP folders were underneath my smart folders rather than above as before) which threw me at first but I quickly got used to it (and actually prefer it now).
Overall the UI seems crisper. The translucent menu bar isn't really my cup of tea but everything else I've seen so far seems to be an improvement visually. It's certainly nice having consistency between windows of different applications.
Spaces so far is working just like I had hoped. I was worried for a while before the release that different windows from the same app might not be able to live in different spaces (a disaster for something like Safari if you have different spaces for different projects). But fortunately my fears were unfounded.
It's a small thing but configuration of Terminal is much much nicer now.
It's always fun looking at what applications people first download when they install a fresh OS. In my case some of my usual suspects come out of the box. I didn't need to download Python 2.5. Nor Subversion. That basically meant TextMate was the only thing I had to install to be able to get right into my open source projects. TaskPaper is the only other thing I've installed so far.
There's still a lot I haven't tried yet. I can't comment on what I think of Stacks yet. Or Quick Look. And I haven't had a chance to try out iChat yet (neither the fun stuff like effects and backdrops nor the serious stuff like application sharing).
But overall I'm delighted by the upgrade so far.
by : Created on Nov. 3, 2007 : Last modified Nov. 3, 2007 : (permalink)
Blogging Month
I haven't blogged much lately but now that I'm back in Boston I'd like to get back into the swing of it.
So, in the spirit of National Novel Writing Month, where the goal is to write 50,000 words of a novel in the month of November, I'm going to attempt to write 50 blog entries this month (not 1,000 words each, though!)
by : Created on Nov. 3, 2007 : Last modified Nov. 3, 2007 : (permalink)
TaskPaper
I've been using a beta of TaskPaper from my favourite micro-ISV for a while now and it is amazing how much it hits the 80-20 point of what I want in a todo list manager.
TaskPaper manages to support projects, tagging, filtering and archiving of done tasks all with a human-readable plain text markup format.
It's just gone 1.0 and I thoroughly recommend checking it out if you run Mac OS X.
UPDATE (2007-10-29): After writing this, Jesse Grosjean offered a free license to people who wrote reviews on their blog. I decided not to take up this offer and mention that fact here in the interest of full disclosure.
by : Created on Oct. 23, 2007 : Last modified Oct. 29, 2007 : (permalink)
Update: Visit to Google and My First Facebook App
I haven't been blogging much the last few weeks—partly because I've been busy at work and partly, I think, because my Facebook status has become the primary way I get telling the world what I'm up to out of my system.
The last week, however, I've been up to some fun stuff. On Saturday, I made my first visit to the Googleplex for the Google Summer of Code Mentor Summit. You can see a photo of us all here. The 'plex felt like a cross between a kindergarten (bright colours, play areas, places to nap) and a top-secret military installation (with security at every corner to make sure you didn't wander off into any restricted areas).
Then from Sunday thru Tuesday, I attended the Graphing Social Patterns conference on the business and technology of Facebook. Had a wonderful time catching up with some longtime friends there (who I hadn't seen for six odd years) as well as getting caught up in the incredible buzz around the Facebook platform. Apparently there's a Facebook conference on every week in the valley now but, not being a local, it was new and exciting for me.
While there, I built my first Facebook app—deployed on Django (of course). I'll say more in subsequent posts—I have a lot more planned.
Now I'm about to hop on a plane back to Australia for a week or two. I'll be working from there but should have some time for some hacking and blogging.
by : Created on Oct. 10, 2007 : Last modified Oct. 10, 2007 : (permalink)
AtomPub Done
AtomPub is now RFC5023. I guess that means I need to get back to finishing django-atompub :-)
by : Created on Oct. 9, 2007 : Last modified Oct. 9, 2007 : (permalink)
Flashcards Beat Harry Potter
Well, not quite. But the number of users on Quisition, my flashcard site, just exceeded the number of users on Potter Predictions. I'm hoping for 1,000 by the end of the year.
by : Created on Sept. 23, 2007 : Last modified Sept. 23, 2007 : (permalink)
Simone Dinnerstein and the Goldberg Variations
I've mentioned before that I have over five recordings of the Goldberg Variations in iTunes. I just increased that by one after purchasing Simone Dinnerstein's new recording on the strength of Tyler Cowen's comments.
It's definitely a lot more "modern" than Gould's interpretation but it is, quite simply, one of the most amazing recordings I've ever listened to. Definitely a candidate for a desert island album.
Of course, as a composer, the desert island candidacy is as much to do with the piece itself as the interpretation. The Goldberg Variations would have to rate as one of the greatest pieces of music ever written. There is pretty nice article on the piece on Wikipedia.
And for extra Goldberg Variation goodness, check out the video of Christopher Taylor playing parts of it on the only double-manual Steinway ever made.
by : Created on Sept. 22, 2007 : Last modified Sept. 22, 2007 : (permalink)
Sneaky Peak at Habitualist
I've already mentioned habitualist without explanation of what it is.
The site now reveals a little more of the concept I'm working on. I should be starting a closed alpha soon.
by : Created on Sept. 19, 2007 : Last modified Sept. 19, 2007 : (permalink)
Clash of Worlds
At the Workshop on Features at the LAGB 2007 conference in London earlier this month, I met Ron Kaplan in person and he told me about the startup Powerset that he's involved in. It was enough of a clash of worlds that I was talking entrepreneurship at an academic conference, but then this week they were announced as one of the TechCrunch40.
It's not that often that these two facets of my life intersect.
Congrats, Ron!
by : Created on Sept. 19, 2007 : Last modified Sept. 19, 2007 : (permalink)
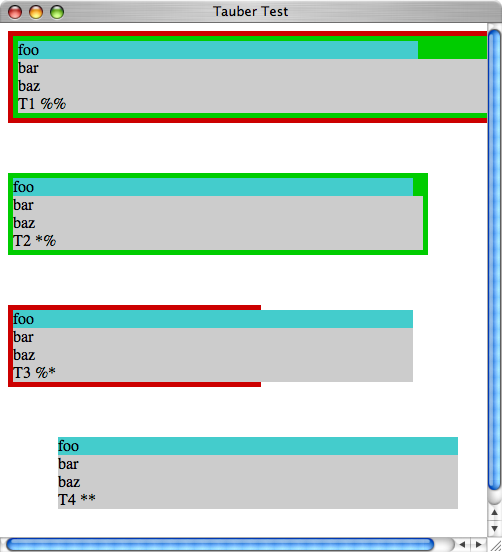
DIV widths
One of the things that's been most frustrating developing websites like Quisition, habitualist and the new Cats or Dogs is the difference between Firefox and Safari (and I guess IE) in determining the width of a block.
Firefox only makes a div as wide as the content needs to be (plus any padding). Safari makes the div as wide as the parent div (minus the parent's padding and the div's own margins).
In different situations, both approaches are desirable.
Short of fixing the width (which does give the same behaviour on both Firefox and Safari) how does one (with CSS) make Firefox behave like Safari or Safari behave like Firefox?
UPDATE: Okay, debugging 101: find the smallest thing that reproduces the problem. It turns out to have to do with multiple embedded floats. The following behaves differently in Firefox and Safari:
<div style="float: left;"> <div style="float: left;"> <div style="width: 400px;">foo</div> <div style="background: #CCC;">bar</div> </div> </div>
In Firefox, bar's background is only as big as the text. In Safari it extends 400px.
UPDATE (2007-09-19): Courtesy of William Bardon, now see http://jtauber.com/2007/09/div_test.html
A screen shot of that, with the window narrow enough that the third test isn't on the same line as the second is at http://jtauber.com/2007/09/tauber_bardon_test_safari.png
{kind=link}
The same thing in Firefox can be seen at http://jtauber.com/2007/09/tauber_bardon_test_firefox.png
{kind=link}
by : Created on Sept. 16, 2007 : Last modified Sept. 16, 2007 : (permalink)
The Long Commute
mValent recently moved from Burlington (the same town in which I live) to larger offices in Waltham. It's not far distance-wise, but anyone who's driven on that stretch of 128 knows it's a nightmare, more than a 5x increase in commute time for me, which is particularly painful given that I haven't had a commute over 5 minutes in eight years (unless you count the 34 hours it takes to get from Perth to Boston).
I may finally have the time to listen to podcasts which means, of course, I'll be relying on Scouta for recommendations.
by : Created on Sept. 15, 2007 : Last modified Sept. 15, 2007 : (permalink)
Demokritos and django-atompub
I just added the following to the django-atompub page on Google Code:
The approach is to start from the specific and only later make it more generic. In other words, I'm building a specific Atom store implementation with all sorts of simplifying assumptions, such as the fact that a collection's path is always /collection/{id}/. Over time, I will make this more generic and django-atompub will be a library rather than an implementation. I'll still keep the specific implementation going though, it will just be called "Demokritos" again and will not be hosted here. Demokritos will be an Atom store that happens to be written on top of Django. django-atompub will be a contributed library for people wanting to add Atom support to their Django sites.
by : Created on Sept. 15, 2007 : Last modified Sept. 15, 2007 : (permalink)
Django Sprint
Today is a world-wide Django sprint. I was at work during the day so couldn't participate but now I'm home, I'm planning on spending the evening working exclusively on my open source django apps:
by : Created on Sept. 14, 2007 : Last modified Sept. 14, 2007 : (permalink)
Many Eyes on Greek Nominal Suffixes
IBM's Many Eyes is a wonderful site for creating and sharing visualizations of data. They recently added a "word tree" visualization which shows weighted suffix trees.
Given I've been working on the inference of inflectional morphology in New Testament Greek for my PhD, I thought I'd upload words with nominal inflection (nouns, pronouns, adjectives, participles) along with their morphosyntactic features (case, number, gender).
For example, to see how dative, plural, masculine nominals end, you just search for occurrences ending in "DPM"
See http://services.alphaworks.ibm.com/manyeyes/view/SgoRsIsOtha66N-wO-cwI2-
At some stage I'll probably do my own visualization that, while not as pretty, will be more customized to inflectional morphology.
by : Created on Sept. 11, 2007 : Last modified Sept. 11, 2007 : (permalink)
I'm With John Gruber
Yesterday, Steve Jobs announced a $200 drop in the price of the iPhone. Some people are claiming it's because it wasn't selling. Others are claiming it's unfair to the people that already bought one (although I'm still waiting for someone to claim the original price was "price gouging"!)
I'm with John Gruber:
Apple didn’t cut the price because demand is low — they set the debut price ridiculously high because demand was ridiculously high. I suspect that for the first few weeks, they were selling iPhones as fast as they could make them. Apple’s being aggressive, not defensive. (And for those of you who’ve already bought one and are pissed about the price cut, if you didn’t think the iPhone was worth $599, you shouldn’t have bought it. That’s how supply and demand works.)
Nicely put, John.
UPDATE: So, Steve Jobs has now said he'll refund $100 to existing iPhone owners. His open letter makes an excellent point, though:
There is always change and improvement, and there is always someone who bought a product before a particular cutoff date and misses the new price or the new operating system or the new whatever. This is life in the technology lane. If you always wait for the next price cut or to buy the new improved model, you'll never buy any technology product because there is always something better and less expensive on the horizon.
by : Created on Sept. 6, 2007 : Last modified Sept. 6, 2007 : (permalink)
Quisition Updates
My flashcard site, Quisition has now been moved over to WebFaction and I took the opportunity to clean up some code and make some incremental feature enhancements.
You can read more about them on the Quisition site. One new feature is the ability to reset long overdue cards. So if you tried out Quisition a while ago and would like to come back without a huge backlog of old cards, this feature is for you!
I've also implemented an alpha version of the testing parts of the site specifically styled for the iPhone. If you're interested in trying it out, email me and I'll tell you how to access it.
by : Created on Aug. 27, 2007 : Last modified Aug. 27, 2007 : (permalink)
Speech Accent Archive
An archive of (at the time of writing) 795 people from around the world, reading the same passage, many entries including a narrow phonetic transcription:
Oddly enough, I found out about it watching an interview of the lovely Zooey Deschanel where she cites it as the latest website she bookmarked.
by : Created on Aug. 25, 2007 : Last modified Aug. 25, 2007 : (permalink)
Stack-Type Vectors, Part II
Previously, we introduced the stack-type vector and showed the identity vector, how inverses are formed and how these stacks are scaled. We haven't yet show how they are added.
Consider the two stack-type vectors marked (a) and (b) in the diagram below:

The geometric way stacks are added is to place them on top of each other and draw lines through each point of intersection, as we have done at (c). The resulting lines, show by themselves in (d) are the resultant addition. (Remember the number of lines drawn doesn't matter, it's how dense they are that determines the "magnitude" of the vector)
With a bit of experimentation, you can see that this definition of addition (in the limit as the lines become closer and closer to parallel) fulfills the requirement that v + v = 2v. In fact, you can establish that all the axioms for linear spaces hold true.
So we have so far seen three different types of linear spaces: one type made up of tuples of numbers, one type made up of arrow-type vectors and one type made up of stack-type vectors. The latter two have the special characteristic that they are geometric: they have some meaning in the context of a manifold.
Because physics models phenomena in the physical world (which can be viewed as a manifold) the vectors used in physics are of this geometric type. Displacement, velocity and acceleration are examples of measurements that can be models as arrow-type vectors. But what about stack-type vectors? We'll get to their use in physics in the next Poincaré Project entry.
by : Created on Aug. 23, 2007 : Last modified Aug. 23, 2007 : (permalink)
Trailing Slashes
The biggest mistake I made in Leonardo was making "foo" and "foo/" mean the same thing. I don't mean directing one to the other with a 301, I mean returning the same content at two different URLs. If you add the fact I listened on both jtauber.com and www.jtauber.com, it meant that every resource had 4 distinct URLs.
That's now fixed: www.jtauber.com redirects to jtauber.com and "foo" is redirected to "foo/".
Unfortunately, most of the del.icio.us bookmark counts I include at the bottom of each page are now effectively reset to 0. While 164 people had bookmarked "poincare_project", none had bookmarked "poincare_project/". Even though the former now redirects to the latter, I've effectively split the vote between past and future bookmarking of that page.
As far as I know, del.icio.us never heeds 301s and updates its database accordingly. Google Reader doesn't seem to either, judging by the continual checking of "/atom/full" in addition to "/atom/full/".
by : Created on Aug. 23, 2007 : Last modified Aug. 23, 2007 : (permalink)
A Very Short Introduction
Via Greg Mankiw, I just found out about Oxford's Very Short Introductions series. Greg has high praise for Mathematics: A Very Short Introduction. When I looked it up on Amazon, I found numerous other books in the series recommended to me: Particle Physics, Cosmology, Music, Economics, Theology, The Brain. There were about 20 that immediately sounded interesting.
As I explored more I found more and more books in the series. Oxford's Very Short Introductions site indicates over 150! Damn, almost every single one of them looks interesting.
As well as individually, they sell them in boxed sets like the "Basics Box" (Philosophy, Maths, History, Politics, Psychology), the "Brain Box" (Evolution, Consciousness, Intelligence, Cosmology, Quantum Theory) and the "Thought Box" (Hegel, Marx, Nietzsche, Schopenhauer, Kierkegaard).
As is generally the case with these sorts of series, I'm guessing the quality varies a lot. Still, it's hard for me to resist buying a large proportion of them right now :-)
by : Created on Aug. 20, 2007 : Last modified Aug. 20, 2007 : (permalink)
jtauber.com Switches to Django
I've spent the last couple of days doing a crude port of Leonardo over to Django including a converter from the Leonardo File System.
I apologize in advance for any problems with the new system.
Functionally, it should already be better than the old one. In particular, categories are handled in a better way which, amongst other things, means that you can navigate through all the pages in a particular category with a previous and next link (see the categories in this post for an example) and category pages list entries with a last modification date and number of comments. Also there is a path of links at the top of any page that isn't at the top level.
I still need to clean up some of the content in light of changes like this so excuse the construction work for the next few days.
Lots more new features planned though, which is one of the reasons I did the port in the first place.
by : Created on Aug. 19, 2007 : Last modified Aug. 19, 2007 : (permalink)
Thoughts on the Social Graph, DataLibre and Aggregation versus Hosting
The recent activity stemming from Brad Fitzpatrick's Thoughts on the Social Graph reminds me of something I was thinking a lot about back in 2004. See especially Mark Atwood's post Five billion social network sites, each about one person on the Social Network Portability list.
The idea I had three years ago was the notion of people hosting their own data and the social networking sites merely being aggregators.
Actually, the way it occurred to me first was in the context of DOAP and the next Advogato but I then generalized the idea in Aggregation Versus Hosting.
Steve Mallett started a mailing list and a website about this same idea, calling it DataLibre. Unfortunately the site no longer exists but here is an announcement of the original site: http://www.oreillynet.com/ruby/blog/2004/09/datalibre_update.html
Steve really drove the vision but I posted numerous thoughts on the idea. Because my blog didn't have categories at the time and I haven't gone back and categorized my old stuff here's a list of my relevant posts:
- OPML Sharing and Polling Security
- More on Aggregation Versus Hosting
- PIMs and DLAs
- Amazon Recommendations and Self-Hosting
- The Road to DataLibre
- Alexa Does DataLibre Right (Almost)
- Flickr and DataLibre
Brad's article (which is a lot more concrete than anything I ever said) seems to be rejuvenating discussion about this sort of thing. See, for example, the post More on social network portability on Plaxo's blog.
by : Created on Aug. 18, 2007 : Last modified Aug. 18, 2007 : (permalink)
Blog Stats
I've posted here every day for the last 10 days straight. I wondered if I'd had such a writing streak before, so I write a quick program that generated a bunch of stats:
(not counting this post...)
- I've blogged 721 entries
- I've never missed a month
- Worst months were August 2006 and April 2007 both with only three posts the entire month
- Best month was March 2005 with 47 posts
- Most number of posts on a single day was six on 14th March 2005 (pi day!)
- Of 477 blogging days, 303 had one post, 118 two posts, 45 three posts and 11 four or more.
and...
- I also had a 10 day streak starting 9th May 2005
- Longest streak was 11 days starting 10th March 2005
by : Created on Aug. 18, 2007 : Last modified Aug. 18, 2007 : (permalink)
List-Unsubscribe
I tend to swing back and forth with my mailing list subscription habits. The two endpoints of the pendulum's path are:
- I rarely read this list, but a have a rule that puts it in its own folder so it's always there if I ever do want to read it
- I rarely read this list and it's cluttering my mailer with 10,000 unread messages so I'll unsubscribe
I'm currently on a swing to the second one.
In one case, I wasn't immediately sure how to unsubscribe from the list, so I looked at the raw headers for the List-Unsubscribe field (described in RFC2369). Sure enough, it was there.
It would be really nice if more mail apps supported this. Okay, it would be really nice if Mail.app supported this :-)
by : Created on Aug. 18, 2007 : Last modified Aug. 18, 2007 : (permalink)
A Lot Many People Talk Like This
I work with a number of people from Maharashtra and I've noticed they all say "a lot many" where I would say "a lot of". I wonder if this is based on a similar construction in Marathi or Hindi or if there's some other reason (analogy with "a good many", for example).
A Google search for "a lot many" (with quotes) shows numerous examples (if you ignore the cases where punctuation separates "a lot" and "many" — I wish you could tell Google not to count those cases).
Anyone have any insight?
UPDATE: I sat down with one of my colleagues and I understand now. In some dialects of Marathi (especially around Pune, for example), the "proper" way to express a large quantity is not just khup but khup sare (खुप सारे). In some regions in Maharashtra, it might be fine to just say khup but the use of both words together is preferred by those that consider the Pune dialect (and those similar) the more "pure". A literal translation to English would thus be something like "a lot many".
by : Created on Aug. 17, 2007 : Last modified Aug. 17, 2007 : (permalink)
PGR2 Maps
A few years ago, my dad won an XBox as a door prize at some event and, for his next birthday, we got him Project Gotham Racing 2 (PGR2). I played it a fair bit too and absolutely loved it.
When I was in Florence at the end of last year, I confess I actually recognized some of the roads from PGR2. I went looking online to see if someone had mapped out all the courses on Google maps but couldn't find anything.
There are some screenshots on Flickr from Bizarre Creations showing the course models. For example at http://flickr.com/photos/bizarrecreations/304326348/ but nothing to really tie the course to the real place.
This evening I found http://www.moondookie.org/pgr2tracks.html which has 12 of the courses drawn over satellite images. It would be nice to have a more complete set, though, and in machine readable form.
Actually, what would be really nice is having the actual models (like the one depicted in the first link). I guess it's too much to hope for that :-) Google's 3D Warehouse is probably best bet of having something anywhere close.
by : Created on Aug. 16, 2007 : Last modified Aug. 16, 2007 : (permalink)
Potter Predictions Now Has Comments
I've added comments to Potter Predictions.
So if you've read the 7th book, head over to http://potterpredictions.com/ and you can comment on each prediction (including arguing if you think I got the "answer" wrong).
by : Created on Aug. 15, 2007 : Last modified Aug. 15, 2007 : (permalink)
Logo Design For Cats or Dogs
I'd like a logo for the upcoming relaunch of Cats or Dogs. I pretty much know what I'd like: the words "Cats or Dogs" with a cartoon cat on the left and a cartoon dog on the right, both leaning on their respective word with a smug look on their face as if to say "of course you're going to pick me".
In return, you'll get a credit (with a link to your site) on the footer of every page.
Email me if you're interested.
by : Created on Aug. 15, 2007 : Last modified Aug. 15, 2007 : (permalink)
Two Google engEDU Videos
I really enjoy the engEDU videos (aka Tech Talks) that Google makes available.
Two interesting ones I recently saw:
- Scaling Laws in Biology And Other Complex Systems by Geoff West
- Metrication Matters by Pat Naughtlin
both in some senses about the same topic of measurement.
Ironically it took me a while to get used to Pat Naughtlin's broad Australian accent. I wonder if that counts as cultural cringe.
by : Created on Aug. 15, 2007 : Last modified Aug. 15, 2007 : (permalink)
Stack-Type Vectors, Part I
Part of the Poincaré Project...
So I've promised a couple of times to introduce stack-type vectors. This is a type of geometric vector that works a little differently than arrow-type vectors. They still meet the requirements of a linear space but their behaviour on a manifold, in particular with regard to a coordinate system on that manifold is a bit different. We'll get into that difference in subsequent posts (as well as talk about where these stack-type vectors show up in physics).
Here is what a stack-type vector might look like in three-dimensions:

Hopefully you can see why I call these stack-type vectors. From now on, though, we'll mostly draw two-dimensional stack-type vectors, but you should still get the same idea.

Note that the number of lines drawn and how long they are are not important (any more than the thickness of the line and shape of the arrow are important in an arrow-type vector). Instead it's the direction the lines are stacked in and how tightly they are packed that characterizes the stack-type vector.
But for a set of these to form a linear space, we need to say how to add them and how to scale them.
Here's how this vector scales (by 2x and by -1x):

Notice that scaling by 2x means the lines are packed twice as closely.
In part II, I'll show how addition of these vectors is defined.
by : Created on Aug. 14, 2007 : Last modified Aug. 14, 2007 : (permalink)
Blogging By Day of the Week
A colleague of mine observed in his reading trends on Google Reader that he reads more blog entries on a Thursday than any other day. His hypothesis was that by Thursday he's bored of office work and other routine stuff and so is more likely to choose to read blogs rather than undertaking other activity.
I checked my own reading trends and, sure enough, I read, on average almost twice as many entries on Thursday than the second most common day. Saturday is the day I read the least number of entries. The thing is, unless I'm travelling or really swamped at work, I generally clear my queue of blogs to read daily. Which means the Thursday thing could be more indicative of when entries are posted than when I take the time to read them.
My colleague points out, his argument could equally apply to posting as well as reading.
So I did a quick three-line Python script to output which day of the week each blog post of mine was made on and a sort | uniq -c dance gave me the following results:
- Monday 67
- Tuesday 106
- Wednesday 108
- Thursday 93
- Friday 115
- Saturday 125
- Sunday 93
So my lowest reading day is my highest posting day and my highest reading day is my equal second lowest posting day.
I guess I don't blog when other people do :-)
by : Created on Aug. 14, 2007 : Last modified Aug. 14, 2007 : (permalink)
49
I'd heard stories of people getting huge AT&T bills (size, not cost) for their iPhone because AT&T lists every single data transfer session as a line item. Sure enough, when I got my bill today, the envelope was thick and inside was a bill 49 pages long.
by : Created on Aug. 13, 2007 : Last modified Aug. 13, 2007 : (permalink)
Math Doesn't Suck
Speaking of Numbers...
A few years ago I was on a flight from Boston to LA when I saw Danica McKellar (Winnie Cooper from The Wonder Years) sitting in business class. I later looked up IMDb to see what she'd been up to and discovered she'd graduated summa cum laude from UCLA with a BS in mathematics.
Furthermore while there, she published a paper that got her a finite Erdős number, making her one of the few people that has both a finite Erdős number (hers is 4) and finite Bacon number (just 2 in her case). (See Wikipedia's Erdos-Bacon number article for a list of other people with both.)
For a while, Danica's had a feature on her website where she answers maths questions posed by fans.
Then, earlier this month, she published a book entitled Math Doesn't Suck : How to Survive Middle-School Math Without Losing Your Mind or Breaking a Nail. I'm clearly not the target audience but if I had a daughter, she could do a lot worse than have Danica McKellar as a role-model.
Way to go Danica!
by : Created on Aug. 12, 2007 : Last modified Aug. 12, 2007 : (permalink)
Installing iWork '08
I just got back to Boston from San Francisco (had a great dinner and chat with Graham Glass last night) and my copy of iWork '08 had arrived.
I'm looking forward to trying out Numbers as I've been eagerly anticipating it for close to two years (I was disappointed '06 didn't have it).
From what I've seen online, I suspect Numbers won't be suitable for some people's high-end number-crunching but for the everyday spreadsheet work I do, it looks like a dramatically better approach than the mainstream spreadsheets of the past.
It will be interesting to see what the "more word processor than page layout" additions to Pages are like as well.
by : Created on Aug. 12, 2007 : Last modified Aug. 12, 2007 : (permalink)
A New and Improved Cats or Dogs Coming Soon
Cats or Dogs turned out to be a great success. It was fun writing and I got a lot of great feedback.
I always meant to go back and add more polish and a bunch more features.
I'm finally starting to do that (reusing some of Potter Predictions too) and, rather than continuing to live off quisition.com, decided to get a dedicated domain: cats-or-dogs.com
Only thing there at the moment is the ability to subscribe to get an email when the site launches. I'll add an Atom feed too, for people who would prefer that means of notification. Both will also help me to gauge interest.
by : Created on Aug. 11, 2007 : Last modified Aug. 11, 2007 : (permalink)
We Like Our Own Stickers Better
Great answer to a dumb question...
by : Created on Aug. 9, 2007 : Last modified Aug. 9, 2007 : (permalink)
Predictive Text
I always used to think it funny on my old Sony Ericsson that the T9 predictive text proposed the name of one of my sisters whenever I was trying to type the name of the other, right up until the last character.
When I try to type my own name on my iPhone, it proposes one of my heroes instead...

If that's predictive text, I guess I have a bright future :-)
by : Created on Aug. 9, 2007 : Last modified Aug. 9, 2007 : (permalink)
In San Francisco
I'm in San Francisco from today until Sunday.
If anyone is interested in catching up Friday evening or Saturday, let me know — we'll see if we can get a Geek Dinner going.
by : Created on Aug. 9, 2007 : Last modified Aug. 9, 2007 : (permalink)
Everything is Miscellaneous
I've mentioned before that I've long held a fascination with taxonomies, classifications systems and the like.
I've also been a long-time advocate of hierarchy being derivative (via ordering of facets) rather than primitive, and of faceted tagging (back in 2005 I called it tag the tags but see Google Code Project Hosting for a great example of how simple tag structure achieves this).
So I'm having a great time (half way through) with David Weinberger's Everything is Miscellaneous which is a wonderful book about these kinds of topics, not just in the computer age but going back to topics like the alphabetization, library catalogs in Alexandria, the Dewey Decimal System, the Periodic Table (and alternatives) and the Linnaean Taxonomy.
The book doesn't fall into the books that changed my mind category but more the I never thought of putting it that way before category.
by : Created on Aug. 9, 2007 : Last modified Aug. 9, 2007 : (permalink)
Linear Spaces: Duck Typing and Tuples
Part of the (very slow moving) Poincaré Project.
We've introduced the general concept of a linear space and shown how it applies to the specific notion of arrow-type vectors.
Recall that a (real) linear space is a set of objects that can be added and scaled. What 'add' means and what 'scale' means are arbitrary as long as the following rules are followed:
the space must form a commutative group under addition, in other words:
for any two elements u and v, u + v is also an element of the space
there is an element 0 called the identity element such that for every element v, v + 0 = v
for every element v there is a corresponding inverse (written -v) such that v + -v = 0
the addition is associative, i.e u + v + w = (u + v) + w = u + (v + w)
the addition is commutative, i.e u + v = v + u
for any real number a and any element v, av is also an element of the space (we say v has been scaled by a)
for any two real numbers a and b and any element v, (a + b)v = av + bv
for any real number a and elements u and v, a(u + v) = au + av
for any real numbers a and b and element v, a (bv) = (ab)v
for any element v, 1v = v
(other properties fall out naturally from the above requirements. For example, it's easy to show that -v must be v scaled by -1, that v + v = 2v and so on. Because these follow from the rules above, they are true of all linear spaces.)
Note that as long as these rules (or axioms) are followed, you have a (real) linear space. It doesn't matter how the elements are actually "implemented". The arrow-type vectors we saw earlier are just one type of linear space.
Programmers might find it useful to think of this as like duck-typing. If it looks like a duck, walks like a duck and quacks like a duck: it is a duck. If you'll pardon the paraphrase, if it adds like a linear space and scales like a linear space: it is a linear space. We never need to peer into the internals of the elements themselves.
Another "implementation" of the linear space idea which is probably familiar to many of you is the n-tuple. Arbitrarily picking n to be 3, the set of 3-tuples form a linear space if we define addition
(m, n, o) + (r, q, r) = (m + r, n + q, o + r)
and scaling
a(m, n, o) = (am, an, ao)
which means, of course, that whatever m thru r are, they must themselves be able to be added and able to be scaled by a real. An obvious choice would be that m thru r are themselves real numbers. Then we have a linear space often referred to as R3.
It is important to note that a tuple-based linear space is not the same as a linear space based on arrow-type vectors. While it may be possible to map arrow-type vectors to tuples (even in a way that is obvious and intuitive), they are not interchangeable and an infinite number of possible mappings exist between an arrow-type vector based linear space and a tuple based one.
It isn't possible to point to some arrow-type vector and say, oh, that's (3, 2, -7) without having first defined how to map the two spaces (which is an extra bit of structure).
One interesting characteristic of the arrow-type vector which the tuple in and of itself lacks, is its geometric nature. An arrow-type vector can be tied to a manifold and mean something in relation to that manifold and indeed this is what makes it a geometric type of linear space. (Remember in a previous post I used the phrase "travel in a particular direction at a particular rate" — this interpretation of an arrow-type vector only makes sense in the context of a manifold)
Next post in the Poincaré Project, we'll look at another type of linear space that is geometric (the one I promised I'd talk about last time) — the stack-type vector.
by : Created on Aug. 9, 2007 : Last modified Aug. 9, 2007 : (permalink)
Atom Format Support Pretty Much Done
Other than:
- support for atom:source,
- checking of co-occurrence constraints and
- more extensive testing
my implementation of RFC 4287 for Django is pretty much done.
I'll wait to see what feedback I get then will release what I have as 0.1. Of course, there's still the protocol work to do.
An interesting thing I noticed: the code for mapping arbitrary objects to atom feeds is not specific to django at all. So the atom.py module could actually be used entirely independently of django. It's a general atom feed generator for python.
UPDATE (2007-08-01): support for atom:source and checking of co-occurrence constraints is now done.
by : Created on July 31, 2007 : Last modified Aug. 1, 2007 : (permalink)
Finally Working On Django-AtomPub
Almost seven months ago, I posted about my plans to move Demokritos over to Django.
Although Django has some support for the Atom Publishing Format (RFC 4287), it's pretty minimal. You can't produce full-content feeds without some hacking and the more advanced features of Atom are not supported. And Django certainly doesn't have support for the Atom Publishing Protocol, which just got approved as an IETF Proposed Standard.
Back at PyCon, I offered to both complete the implementation of the Atom Publishing Format in Django and also implement the Atom Publishing Protocol. I filed ticket #3569 and ticket #3570 to cover these respectively.
Well five months after PyCon, I've finally got off my butt and started working on it.
This afternoon, I started django-atompub at Google Code.
My approach for completing support for RFC 4287 is to first of all build a test model that covers the data model of RFC 4287 feeds and entries. That's pretty much done now and checked in. Now I just need to work on the AtomFeed object that comes with Django and extend it to cover all aspects of that data model. That shouldn't take too much longer.
Then work can begin on the substantial part of the project: support for APP. With Demokritos I've implemented earlier versions of APP before, but the challenge with Django will be trying to maintain loose coupling between the feed and the user's model. Django's existing syndication support takes the nice approach of allowing arbitrary objects to be exposed as feeds and entries. Making that work the other way around (i.e. creating arbitrary objects via APP) will be challenging but, hopefully, very useful.
UPDATE (2007-07-30): The Atom Publishing Format support is almost done. You can check it out at http://code.google.com/p/django-atompub/ and let me know if you have any feedback.
by : Created on July 29, 2007 : Last modified July 30, 2007 : (permalink)
Potter Prediction Results Are In
Rankings are available at
http://potterpredictions.com/rankings/
but people who haven't completed the seventh book should avoid the rest of the site (you have been warned!)
By weighted score, I ended up 130th. My sister on the other hand ranked 13th.
by : Created on July 28, 2007 : Last modified July 28, 2007 : (permalink)
Not that it wasn't already huge, but Facebook seems to be taking off more amongst some of my tribes. If I haven't already sent you an invite and you'd like to connect, look me up!
I've played around with their API a little and it looks promising—expect a Cats or Dogs and Quisition app one of these days.
by : Created on July 22, 2007 : Last modified July 22, 2007 : (permalink)
Multiple Recordings
How many pieces of music do you have multiple recordings of?
In pop/rock, it's mostly limited for me to They Might Be Giants. With 475 TMBG tracks in my library including multiple compilation albums (which probably shouldn't count) that's no surprise. Some of the double-ups are studio versus live versions.
There's a lot of doubling-up on Jazz standards, Mozart and Bach (helped by the fact I have both the complete works of Mozart and Bach as well as many individual recordings).
But what about more than 5 recordings? I can think of only three off the top of my head: two of them are Charlie Parker's Yardbird Suite (my favourite Jazz piece) and Bach's Goldberg Variations (including 3 recordings just of Glenn Gould if you count the Zenph reconstructions).
The third is in a totally different category as I actually have over 10 recordings of it.
It's Prokofiev's D minor Toccata.
by : Created on July 17, 2007 : Last modified July 17, 2007 : (permalink)
Potter Predictions After One Week
Well, it's been exactly a week since I started work on Potter Predictions.
From a development point of view, it's been a big success. I was able to design, implement and deploy everything within 72 hours. Since then I've added numerous features, all of which have been straightforward to implement on top of the existing framework.
So after a week, there are 279 users who have cast 15,078 votes on 154 public predictions. Twice that number of predictions have been submitted, many of which have been rejected as duplicates, some of which I still need to moderate.
Google Analytics suggests there have been 19,361 page views in 1,507 visits from 1,274 unique visitors staying an average of 5 minutes 12 seconds per visit. That means around 22% of visitors sign up for an account.
I paid for Google Adwords for "harry potter predictions" and that yielded 121 clicks from 24,178 impressions on the search page and 475 clicks from 720,224 impressions on the content network. So it appears around half of the unique visitors came from Google Adwords.
In terms of number of users, I have mixed feelings. Things got off to a good start: 100 users on the first day. Another 100 on the second. But then things started to drop off: 50 new users on Friday, 20 new users on Saturday and today is shaping up to only add 10 new users.
A post to alt.fan.harry-potter clearly didn't yield many new users. And my dream of making one of the big Harry Potter sites (which likely would have garnered thousands more visitors, if not users) has not yet come to pass.
But it's hopefully been fun for the users so far. And will be equally so in about a week when the site starts to contain the "answers" to the predictions.
The other nice thing is that the code is reusable, not only for other prediction sites (which I plan to use it for) but also for a number of other sites I have planned in the not-to-distant future. Stay tuned!
UPDATE : It's appropriate that the one week anniversary of one of my more successful (for its age) websites is also the two year anniversary of the framework that made it possible.
by : Created on July 15, 2007 : Last modified July 15, 2007 : (permalink)
Introducing PotterPredictions.com
My new site is
Here's how I describe it on the home page:
This site will let you record your predictions of what will happen (or otherwise be revealed) in the final Harry Potter book.Then on July 21st, when the book is released, the site will no longer accept predictions. A short time after, results will start to be published here and you'll be able to see how you went.
To compare yourself to your friends, you can form groups and, when the results are revealed, you can see how you went relative to your friends. You will also be able to see how your groups (you can be in more than one) compared to other groups.
We hope that this site will provide a little fun while you wait in anticipation of the final book's release.
Thanks to the amazing development efficiency of Python, Django and WebFaction.com, I was able to get this site launched within 72 hours of conceiving of it. There are still features I want to add, but it's (hopefully) a lot of fun already.
by : Created on July 10, 2007 : Last modified July 10, 2007 : (permalink)
New Site Has to Do With Harry Potter
I promised to give a clue about my new site that I hope to launch tomorrow.
It has to do with Harry Potter, which is why it's so urgent to get out. The site really has two phases in its life: one before the book comes out and one after.
If you'd like to try it out before the launch tomorrow, email me.
by : Created on July 10, 2007 : Last modified July 10, 2007 : (permalink)
Another New Little Site Coming Soon
A couple of hours ago I started work on a new little site which I think will be a lot of fun. It's similar in some respects to Cats or Dogs and, of course, is being written with Django. I hope to have it launched by Tuesday or Wednesday but I'll give a clue tomorrow as to what it's about (and why it's so urgent).
by : Created on July 8, 2007 : Last modified July 8, 2007 : (permalink)
You Me Us We Wins Top 20 Place In Songwriting Contest
Nelson just wrote to me to let me know our song You Me Us We, placed in the Top 20 in the Pop Uptempo / Dance category of the 11th Annual Unisong International Songwriting Contest.
by : Created on July 6, 2007 : Last modified July 6, 2007 : (permalink)
Quisition Works Great on iPhone
I just went through a Quisition deck on my iPhone and it worked great.
One of my goals has always been to have flashcards on the go and Quisition on the iPhone gives me that, without any modification to Quisition needed.
If the iPhone had a custom SDK, it would have taken me weeks (or even months) to port Quisition. It may have been slicker, but you can't beat something just working, with no additional effort required. And a certain amount of slickness can always be added later via an alternative stylesheet triggered by user agent.
by : Created on June 30, 2007 : Last modified June 30, 2007 : (permalink)
Got My iPhone
Apple sure knows how to put on a show.
I headed down to the Apple store at the Burlington Mall around 4.30pm. Ended up being 100th in line. Some people had been in line since the morning (which turned out to be completely unnecessary).
Was around 6.20pm before I made it in the store. I was greeted by a handful of Apple Store employees who cheered and clapped me. They made each one of us who had been in line feel like a celebrity. All that was missing was the red carpet.
The on the way out, more cheers and clapping. To top it off, I was then interviewed by a local paper.
Some people thought I was crazy buying it today. The atmosphere made it all worth it.
Will report more once I've actually tried it out.
UPDATE (2007-07-06): The Lowell Sun has the story online. That's my hand, drink, and iPhone bag in the first photo :-)
by : Created on June 29, 2007 : Last modified July 6, 2007 : (permalink)
This Application Is Viewable Only On iPhone
Has anyone faked the User-Agent to see more?
UPDATE (2007-06-29): Now that the iPhone is out, the page (on a real iPhone) has the title "Device Error page" and the body text "If you'd like to view an RSS feed, just enter the feed URL directly into Safari's address bar."
When you do that (e.g. http://jtauber.com/atom/full/) it actually redirects you back to http://reader.mac.com/mobile/v1/{{the feed url}}
by : Created on June 27, 2007 : Last modified June 30, 2007 : (permalink)
Introducing Tintin Movie Info
I've finished putting up the news on the Tintin movie from November 2002 when I first started my previous site thru May 15th 2007 when news broke that Peter Jackson would be taking on a bigger role than simply WETA providing a CG Snowy.
Still more to update, but you can now view the site at http://tintinmovie.info/
by : Created on June 22, 2007 : Last modified June 22, 2007 : (permalink)
Monty Hall Python
The Monty Hall Problem is one of my favourite examples of a counterintuitive solution in mathematics.
It works as follows:
- A car (or some other suitable prize) is placed behind one of three closed doors.
- You, as contestant, pick one of the doors.
- The host of the show, Monty Hall, opens one of the other two doors (making sure to pick one without the car)
- You are then given the option to stay with your original pick or to switch to the other unopened door.
Now, the counterintuitive solution is that you double your chances of winning by switching. This is counterintuitive because Monty opening one door hasn't told you anything new about which of the two remaining closed door is likely to have the car behind it.
Here's how I think about it mathematically: when you pick your door, there is a 1/3 chance it's behind the door you picked and a 2/3 chance it's behind one of the other two doors. When Monty opens one of the doors, he hasn't changed that fact: there's still a 2/3 chance it's behind one of the two doors you didn't pick. It's just now he's narrowed down which of the two doors it could be behind. So there's a 2/3 chance it's behind the door you didn't pick that's still closed as opposed to a 1/3 chance it's behind the door you original picked. So you double your chances by switching.
Sound convincing? Well, some people still like to see it played out. So here is a little Python program that will play 1000 games and show you the proportion that would be won by a stayer and the proportion that would be won by a switcher.
by : Created on June 19, 2007 : Last modified June 19, 2007 : (permalink)
WWDC Keynote
So I watched the keynote this morning and, like many people, was underwhelmed.
Maybe I was expecting too much after Steve's amazing performance announcing the iPhone but there was just nothing to get really excited about. The best part was John Hodgman at the start. Steve's high point (which isn't saying much in this talk) was his faux announcement of all the different versions of Leopard.
Nothing new was revealed about Leopard that excited me. The interesting stuff for me is mostly hidden away at http://www.apple.com/macosx/leopard/technology/unix.html: Terminal 2 (with tabs), Python 2.5, Scripting Bridge support for Python, DTrace support (including for Python). Time Machine and iChat Theater are cool but we already knew all about them.
All evidence continues to suggest Spaces will be application-centric rather than window-centric. i.e. it's not clear to me you can have different Safari windows in different spaces. All the demos talk about having different apps in different spaces but not different windows from the same app. Hard to see how you could divide up activity areas without allowing more than one to have a browser. But maybe that's supported and I just haven't see it yet.
Regarding the "Web as iPhone SDK" announcement: I have no problem with that (and actually talked about it when the iPhone was first announced). It's actually my preferred way of developing applications for the iPhone. But I think Steve presented it the wrong way. It felt too much like "sorry, it's the best we could do under the circumstances".
Am I still looking forward to Leopard? Absolutely. Do I still plan to buy an iPhone at the end of this month? Of course.
I just don't think this was one of Steve's best.
by : Created on June 12, 2007 : Last modified June 12, 2007 : (permalink)
Beautiful App
On the weekend, I came across a piece of software that is so good-looking, it makes me minimize all my other windows just so they don't distract from the beautiful UI of this one.
It's Midnight Inbox from Midnight Beep.
I haven't started to use it yet, so can't comment much on its functionality. But it sure looks nice.
And sorry PC guy—unlike Safari, it's Mac only.
by : Created on June 12, 2007 : Last modified June 12, 2007 : (permalink)
iTunes Plus
I have 8,175 songs in iTunes. 700 of them were purchased on iTunes Music Store.
I just upgraded to iTunes Plus (for the higher quality more than the non-DRM) and took advantage of the limited-time ability to upgrade existing songs.
Unfortunately there were only 23 of them.
UPDATE: Although a normal song takes about 3 seconds to download in my new apartment, many of the iTunes plus upgrades are taking hours and/or timing out. I wonder if they are being served up from a different location that's overwhelmed.
by : Created on June 1, 2007 : Last modified June 2, 2007 : (permalink)
Tintin Site Coming Back
Today is the 100th anniversary of the birth of Georges Remi, the creator of Tintin.
It is also exactly four and a half years since I started marlinspike.org, the first website dedicated to news about the Spielberg Tintin project.
Unfortunately, I neglected to renew the domain a couple of years ago but the good news is, I'm bringing it back at a new location in the next few days (along with all the old rumours from 2002-2004!)
Stay tuned!
UPDATE (2007-06-21): It's back at http://tintinmovie.info/
by : Created on May 22, 2007 : Last modified June 21, 2007 : (permalink)
A Short History of You Me Us We
Being in Australia only half the time (and now less) has made my five year musical collaboration with Nelson Clemente slow moving. We have an album full of songs that we'll eventually get out, but last year Nelson very wisely got himself a real producer and has been working on his solo career in earnest.
One of the songs on his debut EP is actually one of our joint ventures. It has a long history, starting off as a fairly up-beat piano-centric instrumental I wrote in 1993 for a girl called Lucy Orlowsky. The song was imaginatively called "For Lucy". Ostensibly it was to congratulate her on getting an A+ on an essay for Ancient History. Later on I renamed the piece "Ancient History" with the obvious double meaning.
When I first started collaborating with Nelson, he added some very moving lyrics, changed the melody and called it "You Me Us We". I slowed it down and rearranged it for just piano and strings. It was performed a few times, including once on community television.
Then, for his solo EP, Nelson wanted to include a version of You Me Us We that fit the electropop style of the other songs. So I worked with producer Rob Agostini on the version that is now available. The intimate piano work is gone but the up-beat catchiness of the original 90s arrangement is back. And people seem to like it.
like totally one of the best pop songs this year...we fell madly in love with Nelson Clemente's 'You Me Us We'...It's the perfect blend of sparkly pop that will make you feel like the world isn't so bad after all.
Nelson Clemente's 'You Me Us We' is probably our favourite electropop song to be released this year and quite simply put, we can't stop listening to it.
To top it off, it is currently #1 on the ElectroQueer charts for the second week running, beating out Nelson's hero Darren Hayes.
Check out Nelson's Website.
by : Created on May 20, 2007 : Last modified May 20, 2007 : (permalink)
Pied-à-terre
Yesterday, I signed the papers to rent an apartment in Burlington. Every international man of mystery (to use Titus Brown's introductory description of me from PyCon) needs at least one pied-à-terre and this is mine :-)
For the last five years, I've lived in a hotel whenever working in the US. I felt an immediate sense of stability walking out of the leasing office yesterday with the keys to my apartment.
Now I just need to buy a bed and bedding, some towels, toilet paper, a desk and chair, and arrange Internet access and I'm all set! Other furniture, kitchenware and household "essentials" can wait :-)
by : Created on May 17, 2007 : Last modified May 17, 2007 : (permalink)
Peter Jackson to Join Spielberg for Tintin
I've been tracking news on Spielberg's Tintin project for four years now and the breaking news is that Peter Jackson will join forces with Spielberg.
Exciting news indeed and I'll follow up as I find out more.
by : Created on May 15, 2007 : Last modified May 15, 2007 : (permalink)
Lord of the Rings Online
I've been playing in the open beta for the MMORPG Lord of the Rings Online and have been having a lot of fun with it. The game is set in Eriador at the time of the first book. The graphics and gameplay are as good as I've seen in an MMOG but, not surprisingly, it's the content that sets it apart for me. It's not just being able to wander around the Shire, Breeland and Ered Luin—it's that the game designers have done a great job in conveying the rise of evil in those areas in the lead up to the War. In a way the game is showing a large part of what, by necessity was missing in the film adaptations. Of course, there's a huge amount the game designers have had to make up. But from what I've seen so far, it feels authentic.
Although it remains to be seen how they can pull this off over months or years, they have done a pretty decent job of handling the fact the main plot must move on even though players are all at very different stages of the game. There was a Ranger called Strider at the Prancing Pony in Bree when I went there (a Ranger in Ered Luin sent me to talk to him) but presumably later on, I'll be able to see Aragorn in Rivendell. The challenge is that presumably starting players will still see him in Bree.
If you're interested in MMOGs it's worth checking out, even if you're not into the Tolkien legendarium. But if you are, it's obviously an extra treat.
If you play, email me. I'm on the Landroval server.
by : Created on April 15, 2007 : Last modified April 15, 2007 : (permalink)
Python at the Google Summer of Code
Google has announced the successful student applications for the 2007 Summer of Code. The Python Software Foundation is mentoring a total of 34 projects (list) and there are probably almost that many again related to Python but being done outside the PSF.
It will be a great summer for Python. Thanks Google!
by : Created on April 12, 2007 : Last modified April 12, 2007 : (permalink)
I'm Back
I haven't been blogging for the last few weeks because I've been back in Australia packing up all my stuff. Most of it has gone into storage with some stuff being shipped to Boston where I'll be spending most of my time over the next few months.
I'm in San Francisco at the moment, on my way to Boston this afternoon. Regular blogging should then resume, including (but not limited to) posts on the Google Summer of Code, Quisition, the Poincaré Project, Lord of the Rings Online and pre-production on my first feature film.
by : Created on April 11, 2007 : Last modified April 11, 2007 : (permalink)
Learning Morse Code
After adding a Braille card pack to Quisition, I started investigating Morse Code and found some interesting information about two different approaches to learning Morse Code that have got me thinking about more general application to learning.
Firstly, some background information on timing. The Paris Standard timing has a dash three times longer than a dot with the gap between atoms equal to a dot, the gap between letters equal to a dash (=3 dots) and the gap between words equal to 7 dots.
Incidentally, with an inter-word gap, this makes PARIS = 50 dots exactly. Some stuff I've read suggested this is why it's called the PARIS standard but the fact the code was agreed upon at a meeting in Paris might have also been part of it.
Now, coming to learning Morse Code, both the methods I've read about agree on one very important thing: they never lengthen the intra-letter gap to make it easier to learn. Doing so apparently gives the learner too much time to think about the letter as an individual sequences of dots and dashes whereas they need to learn the letter a single unit. Remembering the components with the aid of mnemonics (which I otherwise find useful in other domains) actually prevents the learner from achieving fluency.
But after this, the two methods differ. The Farnsworth method starts with very long gaps between letters and slowly reduces them until full speed is achieved.
The Koch method uses full speed gaps between letters from the outset. However, the learner begins with just two letters and new letters are slowly added.
The stuff I've read suggests the Koch method is more effective at getting people to full speed but that either method is still far superior to trying to learn by slowing down individual letters.
Of course, none of this is from my own experience. Perhaps some readers with CW experience might want to comment.
by : Created on March 27, 2007 : Last modified March 27, 2007 : (permalink)
Django Congratulations
Some congratulations are in order in the Django community.
First of all, congrats to Ned Batchelder and everyone at Tabblo for the acquisition by HP. As far as I know, this is the first acquisition of a company whose product runs on Django.
Secondly, congrats to Adrian, Jacob, James and all the Django developers for the release of Django 0.96. I'm looking forward to switching my Django sites (including Quisition) over to 0.96 as soon as possible (rather than running off the trunk of svn)
by : Created on March 23, 2007 : Last modified March 23, 2007 : (permalink)
Arrow-type Vectors
Part of the Poincaré Project.
When we started to talk about metrics in two or more dimensions I said that "travel in a particular direction at a particular rate" is a kind of vector. This kind of vector can be visualized as an arrow and, with vector addition defined in terms of placing the tail of one arrow at the head of the other, we find that these arrow-type vectors form a linear space.
![]()
The first diagram shows the way addition is defined. The additive identity (the zero-vector) can then just be thought of as the point in the second diagram. The third diagram shows how inverse of an arrow-type vector falls naturally out of the definition of addition. And finally, the fourth diagram shows scaling. From the axioms we defined for linear spaces we know that v + v = 2v for all linear spaces because v = 1v so v + v = 1v + 1v = (1+1)v = 2v.
Visualizing vectors as arrows is common in introductory approaches to vectors in both mathematics and physics. Displacement, velocity, acceleration, force, etc are often described in these terms. However, there are other physical quantities that, while able to be modeled as objects in linear spaces, are best visualized as something other than arrows. In the next Poincaré Project post, I'll introduce this new type of object that I'll initially call a stack-type vector.
UPDATE: next post
by : Created on March 21, 2007 : Last modified Aug. 9, 2007 : (permalink)
Python Primality Regex
Via Simon Willison I discovered this wonderful method of testing primality with a regex by Abigail by way of Neil Kandalgaonkar.
Of course, I couldn't resist porting it to Python, so here it is:
import re def is_prime(num): return not re.match(r"^1?$|^(11+?)\1+$", "1" * num)
although the magic is all in the regex which is copied verbatim from the Perl.
Firstly, the num is turned into a string of 1s so 0 = "", 1 = "1", 2 = "11, 3 = "111" and so on.
The ^1?$ just matches the 0 or 1 case to ensure they don't come up prime. The main part of the regex is the ^(11+?)\1+$.
It basically says match a group of 2 or more 1s repeated one or more times. If the string matches a group of 2 1s repeated one or more times, it's divisible by 2. If the string matches a group of 3 1s repeated one or more times, it's divisible by 3 and so on.
So this regex basically tries to see if the number is divisible by 2, then 3, then 4, etc., stopping with a match once a divisor is found.
And you can find what the lowest divisor was: it's simply the length of the first match group.
UPDATE: I've added Abigail to the credits, per Neil's comment below.
UPDATE: I've removed the phrase "regular expression" as, as pointed out by a commenter on reddit, it's not actually a regular expression.
by : Created on March 18, 2007 : Last modified March 19, 2007 : (permalink)
Python Software Foundation Accepted into Google Summer of Code
Not really any surprise, but I'm still delighted to announce that the Python Software Foundation has been accepted into Google's Summer of Code for 2007.
If you're interested in being a mentor, it's not too late: see my previous post How to be a Python Mentor in the Google Summer of Code.
If you're interested in being a student, we'd love to have you! Check out http://wiki.python.org/moin/SummerOfCode for project ideas.
by : Created on March 15, 2007 : Last modified March 15, 2007 : (permalink)
Generating the Hex Digits of Pi
Seeing as it's Pi Day (3/14) I thought I'd post the little Python script I wrote at PyCon implementing Simon Plouffe's remarkable formula for pi in hex.
def pi():
N = 0
n, d = 0, 1
while True:
xn = (120*N**2 + 151*N + 47)
xd = (512*N**4 + 1024*N**3 + 712*N**2 + 194*N + 15)
n = ((16 * n * xd) + (xn * d)) % (d * xd)
d *= xd
yield 16 * n // d
N += 1
For example, the following code displays the first 2000 digits.
pi_gen = pi()
import sys
sys.stdout.write("pi = 3.")
for i in range(2000):
sys.stdout.write("0123456789ABCDEF"[pi_gen.next()])
sys.stdout.write("\n")
You'll notice that pi in hex begins 3.24 so perhaps I should have waited another 10 days :-)
And if you're wondering why the hex digit after the point is higher that the decimal equivalent, remember that after the point, hex digits are worth less than their decimal equivalents.
by : Created on March 14, 2007 : Last modified March 14, 2007 : (permalink)
How to be a Python Mentor in the Google Summer of Code
This has been announced elsewhere but it shouldn't hurt to mention it here to get on some Python Planets, etc.
If you would like to be a mentor on a Python-related project for Google's Summer of Code this year, here is what you need to do RIGHT AWAY:
- add your name to the Summer of Code Mentors page on the Python wiki
- email me with your name and Google Account (you need a Google Account to participate—a Gmail account is fine)
- join the soc2007-mentors mailing list
If you can't mentor but still have some project ideas, feel free to just join the mailing list for discussion.
by : Created on March 11, 2007 : Last modified March 11, 2007 : (permalink)
Interfaces versus Abstract Base Classes in Python
In his Python 3000 keynote, Guido talked about having marker interfaces to make more explicit notions like "list-like" and "file-like". As I understood it, the idea is to be able to test that an object is "list-like" or "file-like" explicitly rather than arbitrarily pick some attribute on the object to test for as the diagnostic.
What confused me at the time was that Guido was calling this feature "Abstract Base Classes".
To me, this conflates inheritance with polymorphism. Aren't abstract base classes fundamentally about inheritance of (partial) implementation? But surely this isn't what Guido is talking about—he's purely talking about the interchangeability of objects (i.e. polymorphism).
So isn't the term "abstract base class" inappropriate and potentially misleading?
by : Created on March 4, 2007 : Last modified March 4, 2007 : (permalink)
The First 100 Quisition Users
A couple of days ago, the number of user accounts on my flashcard site, Quisition, hit 100.
Of those 100 accounts, only 89 were activated. That means 11 people either entered an incorrect email address or never responded to the activation email.
Of those 89, only 72 created a deck for testing and of those 72, only 57 learnt any cards with that deck.
All of this is understandable given the number of people that came to just try it out or see how I'd used Django in a particular way.
The only statistic that really disappoints me is that, of the 57 that started learning cards, only 1 user hasn't currently got any overdue cards to review. And that user is yours truly, so really my user retention is currently 0%.
Oh well, I'll still continue to improve it. It's been a chance for me to learn Django and I have now learnt all the chemical symbols (and will continue to review them with Quisition).
If anyone has an suggestions on how to improve Quisition, email me or leave a comment here.
by : Created on March 3, 2007 : Last modified March 3, 2007 : (permalink)
Median Age of the World's Population
The other day I was wondering if I'd hit the age where there were as many people younger than me in the world as older than me.
In other words, I wondered what the median age of the world's population is. Yesterday, I was talking to our Chief Marketing Officer about it and we decided to look it up.
Turns out I passed it five years ago. The median age is 28.
The source is the United Nations Department of Economic and Social Affairs/Population Division in their World Population Prospects.
by : Created on Feb. 28, 2007 : Last modified Feb. 28, 2007 : (permalink)
Linear Spaces
Part of the Poincaré Project.
To understand the metric more we need to talk about vectors but to understand vectors, at least in our context, we need to talk about linear spaces.
Remember right at the start of the Poincaré Project, we talked about adding structure to sets. Like most mathematical objects with "space" in their name, a linear space is a set of objects with a particular structure added to the set consisting of relationships between and operations on the objects.
Informally, a linear space adds just enough structure to a set that the elements can be added and scaled. And that's the principal way you should think about them here.
More formally, addition of the elements must be defined in a way that is associative and commutative and such that there exists an identity element and, for each element, an inverse. This makes linear spaces commutative groups.
Further more, there is a notion of scalar multiplication (for our purposes by a real number) such that (if a and b are real numbers and u and v elements of the linear space):
a ( u + v ) = a u + a v
(a + b) v = a v + b v
a (b v) = (ab) v
1 v = v
It is very important to note what the structure of linear spaces by itself does not provide. There is no notion of the length of an element or the angle between two elements. Neither is it possible to multiply elements by each other. They can just be added and scaled.
Often linear spaces are called "vector spaces" and their elements "vectors" but, as we will soon see, it's useful for our purposes to keep "vector" to a more narrow sense.
UPDATE: next post
by : Created on Feb. 28, 2007 : Last modified Feb. 28, 2007 : (permalink)
My Next Camera?
The Canon EOS-1D Mk III (via) is due out in a couple of months. I'm very tempted to start saving for it.

I confess I was a little disappointed it's not full-frame but the other specs are amazing.
by : Created on Feb. 25, 2007 : Last modified Feb. 25, 2007 : (permalink)
PyCon Web Panel
The web panel went well. Rather than me trying to remember what I, or anyone else said, I direct you to James Bennett's excellent notes.
by : Created on Feb. 23, 2007 : Last modified Feb. 23, 2007 : (permalink)
One Laptop Per Child, Python (and Cleese)
I'm sitting in the plenary at PyCon where Ivan Krstic is giving an amazing talk about the One Laptop Per Child project.
Even though the laptops run Linux, most of the "operating system", including things like the filesystem, are written in Python. In fact, the goal is to write absolutely as much as possible of the operating system in Python.
Sounds like the Cleese vision has been fulfilled in a way I never could have imagined!
by : Created on Feb. 23, 2007 : Last modified Feb. 23, 2007 : (permalink)
Off to PyCon
In just over an hour I'll be heading off to Logan airport to catch a flight to Dallas for PyCon.
I'm staying at the Courtyard Dallas Addison/Quorum Drive. I won't be arriving there until after 11pm but, if you're around, email me.
by : Created on Feb. 22, 2007 : Last modified Feb. 22, 2007 : (permalink)
Economics, Computational Neuroscience and Differential Geometry
What do economics, computational neuroscience and differential geometry have in common?
Well, besides all being interests of mine, they also all happen to be the three topics in the PyCon session on science applications I just volunteered to chair. When I saw the topics and that they didn't have a chair, how could I resist?!
It will be on next Saturday afternoon and I'm looking forward to it a lot!
by : Created on Feb. 17, 2007 : Last modified Feb. 17, 2007 : (permalink)
Cats or Dogs After One Week
- 89,584 hits
- 2,495 unique IPs
- 2,533 sessions
- 40,470 questions asked
- 648 questions submitted
- 116 visible at the moment
- 6,696 different pairings of questions
- 32 del.icio.us bookmarks
Random interesting computer-related result:
People who prefer reddit to digg are 2.4 times more likely to prefer PostgreSQL to MySQL but people who prefer digg to reddit are 2.2 times more likely to prefer MySQL to PostgreSQL.
Random interesting non-computer-related result:
People who prefer Obama to Hillary are 6.0 times more likely to prefer letterbox to full screen but people who prefer Hillary to Obama are 50% more likely to prefer full screen to letterbox.
by : Created on Feb. 16, 2007 : Last modified Feb. 16, 2007 : (permalink)
Google Code Project Hosting
I've been playing around with Google Code Project Hosting for one of my smaller projects and it's pretty impressive. Project Hosting basically provides file downloads, a wiki, issue tracking and subversion.
The issue tracking is tag-based but with a little bit of structure to the tag to allow the tags to act like values of arbitrary fields. So far, this works well—probably the simplest way to get extensibility I've seen in an issue tracking system.
It does miss some features that I really like from Trac. There isn't an equivalent to the timeline to see project activity. There's no way to browse different versions of files or do diffs. Hopefully these features will be added in the future.
I'm not necessarily ready to move all my self-hosted projects there, but I'd certainly chose Google Code Project Hosting over SourceForge in an instant.
However, there is one major annoyance. Project Hosting requires you to have a GMail account, not just any old Google Account. This by itself would not be a problem, but it uses the Google Account system for authentication. So to use Project Hosting, you have to log into Google Accounts with your GMail address. This is very annoying if you use other Google services under a non-GMail Google Account. I find myself constantly having to sign out and sign in again, sometimes even just switching between browser tabs that are open on different services provided by Google.
by : Created on Feb. 15, 2007 : Last modified Feb. 15, 2007 : (permalink)
Added Chi-Squared to Cats or Dogs
I added a calculation of chi-squared to Cats or Dogs. This gives it a certain statistical honesty at the expense of some of the fun (because most of the funny results the site generates are not statistically significant and you are now told that). Nevertheless, some of the results are still surprising.
by : Created on Feb. 10, 2007 : Last modified Feb. 10, 2007 : (permalink)
Introducing Cats or Dogs
Okay, just under four hours later, here it is...
Have fun! I look forward to the results.
by : Created on Feb. 9, 2007 : Last modified Feb. 11, 2007 : (permalink)
New Little Site Coming Soon
A few years ago, I read about a phenomenon that I always wanted to test for myself, but I could never work out how.
Well, tonight, over dinner, I came up with an idea for a fun little website that would test for said phenomenon and also a bunch of other interesting stuff.
So armed with half a bottle of Coke Zero and a can of Red Bull, I'm going to spend this evening coding it up.
What is it? Well, you'll just have to wait a few hours and see :-)
by : Created on Feb. 9, 2007 : Last modified Feb. 9, 2007 : (permalink)
Yahoo Pipes and Reading Plans
Congratulations to the team behind Yahoo Pipes. As I've said to a lot of people recently, I still think Yahoo is a very exciting company to watch.
One thing I'd like to see possible with Pipes, which I couldn't work out how to do in the 10 minutes I played with it, is reading plans of the sort I described back in a post in 2004.
I've thought about reading plans like this for the Poincare Project. Basically, each reader gets a feed specific to their start date which, starting from the beginning, just adds a new item at some set interval, either daily or weekly.
Recently it occurred to me that this would also work for things like running plans as well (the "5K in 5 weeks" sort of thing).
So the pipe would take as an input a feed, a start date and an interval and introduce the nth oldest item in the feed on day = start date + (n -1) * interval. The input feed would have to be a complete feed, not a sliding window.
But I couldn't see quite how to do this in Pipes as it currently stands.
Of course, one could whip up a quick website that did the same thing too. Hmm, maybe someone already offers this service.
by : Created on Feb. 9, 2007 : Last modified Feb. 9, 2007 : (permalink)
Quisition Launched
My flashcard site, Quisition, has now been launched. Actually, it's been available for the last week but I wanted to test things out a little before announcing anything publicly.
You can sign up at:
http://www.quisition.com/
As of a couple of days ago, support exists for user-contributed cards, although no bulk import yet. That will come shortly.
Implementing this with Django has been a delight. Like Python in general, using it a combination of productive and fun that makes you just want to come up with more ideas you can develop with it.
by : Created on Feb. 5, 2007 : Last modified Feb. 5, 2007 : (permalink)
Going to PyCon
I'd been putting off booking PyCon because I wasn't sure which of three continents I was going to be on that particular weekend.
But now that I'm fairly confident I'll be in the US, I've registered for PyCon, booked my flight and hotel.
See you there!
by : Created on Feb. 3, 2007 : Last modified Feb. 3, 2007 : (permalink)
Reverse Templates
I've been using Django's templating language a lot recently and it pretty much hits the right 80-20 point for me. In general, a templating language with basic conditionals and for-loops is a great way of specifying how a complex data structure is to be serialized as a string. It certainly beats writing generation code.
But that got me thinking—if a template can take the place of generation code to go from abstract data structure to surface syntax string, can it also take the place of parsing code to go from surface syntax string to abstract data structure?
Obviously some templates are irreversible but a good number of them should be usable to driving parsing.
So imagine you have a data structure which is a list of people with a first name and last name and you have a template like this (in Django's templating language):
<people>
{% for person in person_list %}
<person><first>{{ person.first_name }}</first><last>{{ person.last_name }}</last></person>
{% endfor %}
</people>
Note that I've deliberately chosen element names which differ from the names used in the data structure.
It would be relatively straightforward to create a person_list data structure from an XML instance using this template in reverse.
One challenge is that there's no indication of whether the person variable is a dictionary or an instance of, say, a Person class with attributes first_name and last_name.
Has anyone done this sort of thing? I can't imagine it's anything new.
Note that, despite the example, it's not restricted to XML, so this isn't just an XML data binding. It could be used for many appropriate file formats. vCard comes to mind, for example.
by : Created on Feb. 3, 2007 : Last modified Feb. 3, 2007 : (permalink)
IM Access in Hotels
I spend 3-6 months of the year in hotels. My experience in my current hotel is that:
- Skype works
- Yahoo! IM works
- Microsoft Messenger sometimes works
- iChat/AIM never works
This is pretty typical in hotels I stay at. What are other people's experiences?
by : Created on Jan. 25, 2007 : Last modified Jan. 25, 2007 : (permalink)
Quisition Almost Ready for Deployment
The Django version of Quisition is just about ready to be deployed. I'm just waiting for the chapter on deployment in the Django Book to be published :-)
The Django version will be an open beta, even though it is a complete rewrite of the previous closed beta. I haven't added much functionality to what was in the closed beta. In particular, you can't add your own cards yet (but that will come in the next few weeks).
The biggest improvement (besides being written using Django) is that I now separate the notion of a "pack" from a "deck". A pack is a collection of cards distributed as a single unit. A deck is a collection of packs that are to be tested as part of the same session.
The main motivation is in cases like learning vocab from a book, where it is easier to manage a pack of cards per chapter but, when it's time to learn a particular chapter, you just want to add the cards in that pack to your deck.
So say you're learning Biblical Greek. You could create a deck for "Biblical Greek" and add to it the pack for chapter 1. When you are ready to learn chapter 2, you can add the chapter 2 pack to your "Biblical Greek" deck. This will also facilitate the creation of new cards for a deck that has already been started on.
by : Created on Jan. 20, 2007 : Last modified Jan. 20, 2007 : (permalink)
Metrics in Two or More Dimensions
In the previous Poincaré Project post about coordinate systems and metrics, we introduced the notion of a metric that tells us how quickly a coordinate changes on a one-dimensional manifold. Let's now extend that to two (or more) dimensions.
Imagine that you're at a particular point on a two-dimensional manifold. If you head off in a particular direction from that point at a particular rate, your coordinates will change. The metric tells you, from a given point, the rate of change of each of your coordinates given travel in a particular direction at a particular rate.
Or to make it more concrete, imagine you're in a boat on the ocean and you start to travel due east at ten knots. The metric will tell you the rate of change of longitude.
Note three things:
- the metric is different at different locations. In our ocean example, the metric will be different at different latitudes.
- the "travel in a particular direction at a particular rate" is a kind of vector.
- the metric, at a particular point, is a linear function of that vector. If you head off twice as fast, the coordinates will change twice as fast, and so on.
To better understand what kind of mathematical object this metric is, we'll need to better understand the notion of a vector.
UPDATE: next post
by : Created on Jan. 15, 2007 : Last modified Jan. 15, 2007 : (permalink)
Quisition on an iPhone
I was thinking yesterday about how cool it would be to have a little Quisition client for the Apple iPhone so you can review your flashcards while standing in a line or catching public transport, etc.
But then I thought, what if Apple really doesn't allow 3rd party applications on the iPhone?
Then I realised: it does allow 3rd party apps. They are called the Web.
UPDATE: The same point is made by Jonathan LaCour and Mark Baker
by : Created on Jan. 13, 2007 : Last modified Jan. 13, 2007 : (permalink)
Open Source Second Life Client
Second Life demonstrated they had a clue a few years ago, with their IP policy on user-created content. I actually think I first heard about Second Life because of a Slashdot article on that policy.
Now Second Life has decided to open source their client and their FAQ about it demonstrates again that they do indeed "get it".
Open sourcing the client, of course means exposing the API (the latter could be done separately, of course, but I don't think it had been until now). This really excites me because of the kind of mashups this will lead to, in both directions.
Very interesting times.
UPDATE: Digging a little deeper, it looks like it's been possible for a while to make XML-RPC calls from within Second Life to the "real world".
by : Created on Jan. 8, 2007 : Last modified Jan. 8, 2007 : (permalink)
Demokritos Moving to Django
I've previously written about the fact I'm porting Quisition to Django (a port which is going well, by the way).
I've decided that it would be useful for me to port my Atom Store, Demokritos, to Django as well. Much of what's left to do in Demokritos is provided by Django so I think it's a good move.
I'm not aware of any APP implementations for Django, so that will be a useful contribution I can make.
One of the nice things about doing my own implementation from scratch was I could build in a REST philosophy from the foundation up. Hopefully Django won't get in the way in this regard.
by : Created on Jan. 5, 2007 : Last modified Jan. 5, 2007 : (permalink)
Why Narrow Depth of Field Makes Large Objects Look Tiny
37 Signal's review of 2006 posts, reminded me of their post about Olivio Barbieri's photography where he uses a tilt-and-shift lens to bring only part of an aerial photograph into focus.

The most obvious impact is the large object now looks like a tiny model. There are various tutorials about how to achieve a similar effect in Photoshop with gradient lens blur. See, for example, Fake Model Photography.
But why does this work? Why does a narrow depth of field make large objects look tiny?
For a fixed film (or sensor) size, depth of field depends on the focal length and aperture of the lens and how far the subject is away from the camera.
As photographers well know, a photo taken with a 200mm lens will have a much narrower depth of field than one taken at 16mm. Similarly, a photo taken at f/1.2 will have a much narrower depth of field than one taken at f/22.
But it's the role of subject distance in depth of field that makes photos like the one above look like models. If we assume 35mm film (or a full-size sensor) and a 50mm lens at f/4, then focusing at 1m will lead to a depth of field of around 10cm whereas focusing on a subject at 10m will lead to a depth of field of around 10m (from roughly 7m-17m). In fact, for our 50mm f/4 case, any subject over 25m away will have its background completely in focus.
So if you see an image of a subject that's 25m away and anything beyond that quickly goes out of focus, then either you've got a very open lens or a very long lens (or both).
Now imagine if the subject is 500m away and is starting to get out of focus by, say, 510m. What sort of focal length or aperture would this require? A 50mm lens would have to have an aperture on the order of f/0.004 - i.e. 12.5m!! If you wanted a more reasonable aperture like f/2.8, your lens would have to have a focal length of around 1350mm.
So you can see that a photo where a point 500m away is in focus but starting to get out of focus by 510m away is impractical to take. The eye knows this. So an alternative interpretation when looking at the photo is to assume it's not 500m away but is actually, say, 500mm away and is much smaller. Having a point 50cm away in focus and 51cm away starting to get out of focus is easily achievable with, say, a 50mm lens at f/4.
Note that I'm being generous with these calculations. When I say "starting to get out of focus", I'm talking about the earliest point at which you could tell on standard 35mm film. This may actually be closer to the subject than I've assumed. But that only makes the point stronger. If we were to require the focus at 500m to be going by 501m, for example, even an f/1.2 lens would have to be 2.7m long.
(btw, I did all these calculations using Dudak's Depth-of-Field Calculator)
by : Created on Jan. 4, 2007 : Last modified Jan. 4, 2007 : (permalink)