James Tauber's Blog 2008
blog >
Marking for Deletion in Django
Often you want to give the user the ability to delete objects but enable them to recover them if they change their mind.
One way to do this is to have a boolean flag on the model. The problem with this is
- you have to have the flag on all associated models involved in the object graph to be deleted
- you have to then filter all your queries based on that boolean flag (error prone and inefficient)
An alternative is to have a separate model for the deleted objects. i.e. DeletedFoo alongside Foo, DeletedBar alongside Bar. The schemas are similar (although some foreign keys are to their deleted counterparts instead) and objects are moved from one table to another when deleted (or undeleted).
This has certain advantages over the first approach, but does mean you have to create twice as many models.
A third approach which just occurred to me is to serialize the object graph to be deleted and store that in the database in a single table row. With Django's existing ability to calculate object graphs for deletion and also to load and dump json, this may be fairly straightforward to implement in a generic fashion.
Pinax is currently using the first approach but I'm interested if people have tried the third approach or secret option number four I don't know about yet.
by : Created on Dec. 19, 2008 : Last modified Dec. 19, 2008 : (permalink)
Screencasting Competition Reminder
Firstly, a reminder that there are now just under two weeks to go until the deadline for the First Pinax Screencasting Competition.
I've added a new feature to the site to let you register your interest in participating in the contest, even if you're not yet ready to submit.
If you think you might be making a submission, I strongly recommend you register interest. This will let us gauge whether we have enough people and also lets us contact you (assuming you confirm an email address) in case things change.
by : Created on Dec. 2, 2008 : Last modified Dec. 2, 2008 : (permalink)
Blog Month Over
Well, I did it! I managed to do at least a post a day for the whole of November.
And I also achieved a goal I had that I didn't mention in advance: I wanted to do 50 posts.
I hope you at least enjoyed some of the blog posts.
I will soon finish off the final part of the Voronoi canvas demo and also the song project, but you'll forgive me if I take it easy. Attempting to do 50 posts was actually a lot more stressful and time consuming than I thought it would be.
That said, 30 days is enough to build a habit. I may find it hard NOT to post regularly now. At least I won't feel I HAVE to, though :-)
UPDATE: BTW, any novelists reading make their 50k for NaNoWriMo?
by : Created on Nov. 30, 2008 : Last modified Nov. 30, 2008 : (permalink)
More Thoughts on a New Language
In Thoughts on a New Language I said:
This relates to the whole concept of the "dictionary created by executing a block of statements". I find this notion of a "block of statements" being a first-class object appealing. Imagine a function that, instead of having a return value, simply returns its bound local variables. I guess Python modules are pretty much that. But I'm thinking of the notion within a file.
There are actually three places where Python uses a block of statements to populate a namespace:
- modules
- function bodies
- class definitions
But imagine that it was a first class object. I'm not really thinking about syntax yet, but one could imagine
{ x = 5 y = x + 2 }
or
block: x = 5 y = x + 2
as possibilities for anonymous blocks. To bind the block to a particular variable, we could therefore say:
foo = { x = 5 y = x + 2 }
or
block foo: x = 5 y = x + 2
Now, what if following on from the previous post and ideas from prototype-based languages like Self, Javascript and Lua you could specify a parent to be traversed in case the block didn't have the requested value. Would there be special syntax for specifying the parent or would it just be a value in the block like __parent__?
foo = { __parent__ = bar y = x + 2 }
or
block foo(bar): y = x + 2
In either case, would the evaluation of y be lazy or not?
What about multiple inheritance, which isn't commonly found in prototype-based languages?
Also, would we want to have the notion of parameterized blocks? With the free variable explicit:
foo(x) = { y = x + 2 }
or implicit:
foo = { y = x + 2 }
?
And would you then want to be able to bind that free variable at a later date:
foo % { x = 5 }
assert foo.y == 7
(just to arbitrarily pick % to use as the operator symbol)
Also, taking a cue from an offhand remark in Steve Yegge's Universal Design Pattern post about this sort of stuff ( HT: Jonathan Hartley) imagine you have a monster objects like
orc = { hp = 10 } warg = { hp = 5 }
and you wanted to capture the notion that a boss monster has 2 times the hit points of a normal monster of that prototype. Would you use inheritance without binding the __parent__ yet:
boss = { hp = 2 * __parent__.hp }
and later:
orc_boss = boss % { __parent__ = orc }
?
Could we use boss(orc) as equivalent to boss % { __parent__ = orc } ?
Some interesting possibility here, just playing around with the notion of a block as first class object with inheritance and parameterization.
And another crazy though: could this language have something akin to list comprehensions but for these blocks so you could compactly define them programmatically where appropriate? This is a contrived example, but Imagine you have a list of strings and you want to create a block that uses those strings as variable names, all set to an initial value of 1.
That is, you want to get
{ foo = 1 bar = 1 baz = 1 }
from var_list = ["foo", "bar", "baz"]
The main challenge seems to be just coming up with syntax for turning strings into variable names. But imagine (just for the sake of example) that ~x meant the variable whose name is the value of x. Then you could (possibly) do something like:
{ ~x = 1 for x in var_list }
This is all just thinking aloud :-)
by : Created on Nov. 30, 2008 : Last modified Nov. 30, 2008 : (permalink)
Endo vs Exo
Yesterday I was starting to get nervous about the path I'd started to go down with the generic groups app for Pinax. I was basically building a single centralized app through which different types of groups would be managed via configuration. I had a good chat with Eric Florenzano about it and we agreed that it just felt wrong but I couldn't think of an alternative.
Then this morning I had a brainwave—a shift in approach that I described on the mailing list as an "exo" approach rather than the previous "endo" approach. Instead of having a single, centralized "groups" app that's highly configurable and lets you plug different pieces in, I realised a better approach would be to simply provide the building blocks for site developers to create their own group apps bottom-up.
The advantage of the "exo" approach is that it makes group customization more like normal Django development. It's more flexible if you want to do some things differently.
After thinking about it some more, it occurred to me that the endo vs exo distinction is quite important when crafting extensible software. It's not that exo approach is always better. It's just different.
The endo approach is that of a framework whereas the exo approach is that of a library. Even a single system like Django may have some aspects that are endo and others that are exo.
An endo approach says to a developer: "we'll provide you the core with slots you can plug your pieces into". An exo approach says to a developer: "we'll provide pieces you can plug together yourself".
In Pinax, django-notifications takes a more endo approach (you register your notification types with the notification subsystem) whereas django-mailer takes an exo approach (it's just there when you want to send mail).
If you need to "register" an entity, an endo approach is probably being used.
If you put your B in the configuration of A then A is endo. Whereas if your B just calls A to do something then A is exo.
Seems a useful distinction. What do people think?
by : Created on Nov. 29, 2008 : Last modified Nov. 29, 2008 : (permalink)
Voronoi Canvas Tutorial, Part III
In Part I, we wrote some code that enabled the user to draw points on a canvas (as long as they weren't too close to an existing point. In Part II we added the drawing of a horizontal line wherever the mouse is.
Next we're going to draw one more type of object which will be at the heart of Fortune's algorithm for Voronoi diagrams. Remember earlier this month in From Focus and Directrix to Bezier Curve Parameters I wanted to be able to calculate quadratic Bézier curve parameters from a focus and horizontal directrix. Now I can explain why :-)
A point (called the focus) and a line (called the directrix) are enough to define a parabola. For Fortune's algorithm, I need to, for each point and for the sweep line, draw the corresponding parabola. The canvas element doesn't have a parabola-drawing primitive. However, it does support Bézier curves.
A quadratic Bézier curve is actually a section of a parabola, so I what I wanted was a way of converting the focus and directrix into the parameters for a quadratic Bézier curve that canvas would understand. That was the motivation for the mathematics in that post.
Implementing those equations in Javascript gives us:
function drawParabola(fx, fy, dy) { var alpha = Math.sqrt((dy*dy)-(fy*fy)); var p0x = fx - alpha; var p0y = 0; var p1x = fx; var p1y = fy + dy; var p2x = fx + alpha; var p2y = 0;
context.strokeStyle = "rgb(100, 100, 100)"; context.fillStyle = "rgba(0, 0, 0, 0.05)"; context.beginPath(); context.moveTo(p0x, p0y); context.quadraticCurveTo(p1x, p1y, p2x, p2y); context.stroke(); context.fill(); }
This not only draws the parabola but fills the region above it (which is relevant to our purpose).
Now all we need to do is run that for each point:
function drawParabolae(dy) { $.each(points, function() { if (dy > this[1]) { drawParabola(this[0], this[1], dy); } }); }
and then add a call to that function to our mousemove handler:
... context.clearRect(0, 0, 600, 400); drawHorizontalLine(oy); drawParabolae(oy); redrawDots(); ....
You can see the result here. I was actually surprised how snappy it is, even with a lot of points. Using the Bézier curve rather than drawing the points manually was definitely the way to go.
If you think about the fact that a parabola is the locus of points equidistance from the focus and the directrix you can start to see how Fortune's algorithm is going to work. I'll make that more explicit in the next and final post.
by : Created on Nov. 29, 2008 : Last modified Nov. 29, 2008 : (permalink)
Bayesian Classification of Pages on This Site
A year ago, in Automatic Categorization of Blog Entries, I talked about automatically categorizing (or at least suggesting categories for) blog posts using a Bayesian classifier.
I finally decided to give it a go, using Reverend.
To train it, all I basically did was:
from reverend.thomas import Bayes
from leonardo.models import Page
guesser = Bayes()
for page in Page.objects.all():
for category in page.categories.all():
guesser.train(category.term, page.content)
Let's pick 10 random blog entries and see how it goes guessing them:
- Pinax Progress III (nothing conclusive)
- The Big 040 (personal 38.7%) CORRECT!
- TeX for Leonardo (leonardo 42.8%) CORRECT!
- Disclosure: Trying Out Google Analytics (nothing conclusive)
- Demokritos 0.1.0 Released (nothing conclusive)
- Programming Languages I've Learned In Order (software craftsmanship 44.8%) CORRECT!
- New Site Look (nothing conclusive)
- Implementing the Unicode Collation Algorithm in Python (nothing conclusive)
- Leopard After Two Weeks (os x 43.5%) CORRECT!
- Film Project Update: A Little More Editing (nothing conclusive)
By "nothing conclusive" I mean that the highest guess was less than 2%. It is interesting that guesses were either < 2% or were around 40% and, in the latter case, they were always correct. So at least no false positives. I wonder what the reason for the false negatives were, though.
Next I tried it against all pages (that had a category). There were 284 cases where no prediction over 5% was made. But in the 288 cases where a prediction over 5% was made, in 287 cases the prediction was correct. In only 1 case was a wrong prediction over 5% made. And it was simply that the classifier thought poincare project should have been tagged "poincare project" :-)
So the precision was basically 100% but the recall 50%.
by : Created on Nov. 29, 2008 : Last modified Nov. 29, 2008 : (permalink)
Voronoi Canvas Tutorial, Part II
In the first part, we implemented the ability to draw dots on the canvas.
Now we're going to draw a horizontal sweep-line where ever the mouse is. The reason for doing this will become clearer in the final two posts.
Here's our function for drawing the horizontal line:
function drawHorizontalLine(y) {
context.strokeStyle = "rgb(200,0,0)";
context.beginPath();
context.moveTo(0, y);
context.lineTo(600, y);
context.stroke();
}
Because we're going to want to clear the canvas every time the mouse moves, we need to be able to redraw the dots. Fortunately, we stored the coordinates in the points array so we can just write:
function redrawDots() {
$.each(points, function() {
drawDot(this[0], this[1]);
})
}
And then finally hook this up to the mousemove event:
$('#canvas').mousemove(function(e) {
var pos = $('#canvas').position();
var ox = e.pageX - pos.left;
var oy = e.pageY - pos.top;
context.clearRect(0, 0, 600, 400);
drawHorizontalLine(oy);
redrawDots();
});
You can see the result after this second stage here.
Now, the fact we have points and horizontal lines might give you a clue as to what's next, particularly in light of a post of mine earlier this month :-)
by : Created on Nov. 28, 2008 : Last modified Nov. 28, 2008 : (permalink)
Broken Bots
This site is being bombarded by requests from a bot of the form:
GET <real_path_to_blog_post>/form.add_comment/
Now, each page does have a form with class="add_comment" and I have jQuery that references $('form.add_comment'). But what kind of broken bot is trying to follow those as links?
That's a rhetorical question. I can tell you the answer:
Mozilla/5.0 (compatible; SkreemRBot +http://skreemr.com)
But I do notice bots accessing all sort of weird URLs. I don't mean looking for exploits—I mean what just appear to be bugs.
It's annoying given each 404 gets emailed to me :-)
by : Created on Nov. 28, 2008 : Last modified Nov. 28, 2008 : (permalink)
Thoughts On A New Language
My favourite rejected/withdrawn Python Enhancement Proposal (PEP) is Steven Bethard's PEP 359 based on an idea by Michele Simionato. That's not to say I disagree with Guido not wanting it in Python, but I like aspects of the idea conceptually as part of a possible Python-like language.
Consider the class statement (take from the PEP):
class C(object): x = 1 def foo(self): return 'bar'
This, as the PEP points out, is equivalent to:
C = type('C', (object,), {'x':1, 'foo':<function foo at ...>})
And more generally:
class <name> <bases>: __metaclass__ = <metaclass> <block>
is syntactic sugar for:
<name> = <metaclass>("<name>", <bases>, <dictionary created by executing block>)
The PEP points out that the class statement nicely avoids the need to mention the name twice and also does the task of executing a block of statements and creating a dictionary of the bindings that result.
It then proposes a make statement of the following form:
make <callable> <name> <tuple>: <block>
that would basically make the class statement syntactic sugar usable for other things. See the PEP itself for a bunch of interesting this this would allow in Python. I certainly think it makes metaclasses clearer.
But my interest isn't so much in Python, but just thinking about a language where something like this is core.
On a related note: think of relationship between Python function definition statements and lambda expressions. One thing I like about Javascript is that the syntax for named and anonymous functions are so similar. One thing I like about Java is that you can have anonymous classes. I wonder if all this could be supported with one core syntax.
This relates to the whole concept of the "dictionary created by executing a block of statements". I find this notion of a "block of statements" being a first-class object appealing. Imagine a function that, instead of having a return value, simply returns its bound local variables. I guess Python modules are pretty much that. But I'm thinking of the notion within a file.
One could argue Python classes are almost that, but they carry with them two additional features—inheritance and instantiation—that would be, I think, interesting to separate out.
Inheritance could be separate and could be a general property of dictionaries. I think it would be interesting and potentially useful to have dictionaries with bases. Of course it's possible to implement such a notion in Python now (see my final remark in this post).
Because of these other characteristics of inheritance and creating a dictionary from executing a block of statement, Python classes can be useful without ever instantiating them. So I think it would be interesting to have a language where instantiability is just another characteristic that can be added on to a dictionary. Of course, Python lets you do that to some extent now with special methods such as __new__ and __call__.
Which leads me to my final thoughts. While I still think it would be fun to explore a language whose fundamental concepts are built along the lines I've been talking about, I think it is worth noting that Python does pretty much let you implement things this way right now. The biggest takeaway for me from Guy Steele's talk was that a good language is one that can take common patterns and turn them in to things that look like primitives of the language. You just need to look at most Python ORMs to see an excellent example of that.
UPDATE: Now see More Thoughts on a New Language
by : Created on Nov. 28, 2008 : Last modified Nov. 28, 2008 : (permalink)
Voronoi Canvas Tutorial, Part I
Earlier in the month, I introduced Voronoi Diagrams with some Python code for brute-force calculation. There are a number of better algorithms and I'd like to talk about one discovered by Steven Fortune. Rather than implement it in Python, though, I wanted to use it as an opportunity to teach myself how to use the canvas element to build an interactive demonstration of Fortune's approach.
So this is part one (of three four) showing how to use the canvas element (in conjunction with jQuery) to demonstrate Fortune's algorithm for calculating Voronoi diagrams. In this part, we'll just do enough to let the user pick the points.
The canvas element was originally developed by Apple but is now implemented not only in Safari but also Firefox and Opera). It is part of the HTML5 effort.
So first of all, here's our HTML:
<canvas id="canvas" width="600" height="400"
style="border: 1px solid #999;"></canvas>
<div><button id="clear-button">clear</button></div>
Next, we'll declare an array called points which will store the (x, y) coordinates of our points.
var points = [];
We don't want the user to draw points too close to one another, so anyClose is a utility function that tells us if a given (x, y) is too close to an existing point. It in turn uses a utility function distance which calculates the distance between any two points. Note that anyClose uses jQuery's each to iterate over the points.
/* calculate distance between (x1, y1) and (x2, y2) */
function distance(x1, y1, x2, y2) {
return Math.sqrt((x2 - x1) * (x2 - x1) + (y2 - y1) * (y2 - y1));
}
/* are there any points close to (x, y) ? */
function anyClose(x, y) {
var result = false;
$.each(points, function() {
if (distance(x, y, this[0], this[1]) < 20) {
result = true;
return false; // break out of each
}
});
return result;
}
Now we get to the actual canvas bits. Operations are performed on a drawing context which we can get in jQuery with:
var context = $('#canvas')[0].getContext('2d');
Here is a function for drawing a black dot at (x, y):
function drawDot(x, y) {
context.fillStyle = "rgb(0,0,0)";
context.beginPath();
context.arc(x, y, 2, 0, Math.PI*2, true);
context.fill();
}
All that remains now is to hook up our event handlers. First, the click event on #canvas:
$('#canvas').click(function(e) {
/* e will give us absolute x, y so we need to
calculate relative to canvas position */
var pos = $('#canvas').position();
var ox = e.pageX - pos.left;
var oy = e.pageY - pos.top;
/* only draw dot and add to points list if
no other points are close */
if (!anyClose(ox, oy)) {
drawDot(ox, oy);
points.push([ox, oy]);
}
return false;
});
And second, the clear button:
$('#clear-button').click(function() {
points = [];
context.clearRect(0, 0, 600, 400);
});
You can see the result here.
by : Created on Nov. 27, 2008 : Last modified Nov. 27, 2008 : (permalink)
Song Project: Fattening Things Up
So this is where we left off our song project:
download if embed doesn't work
To me it feels a bit thin. To fatten it up, we're going to add a nice phat synth and crunchy guitar. Here's the synth riff:
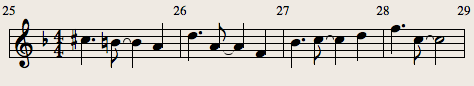
And here is what it sounds like:
download if embed doesn't work
Now here's the guitar riff:

It's just the chords played either as open fifths or octaves with a lick at the end. Notice, though, that (except for the last measure) it's accented 2+3+3 in contrast to the 3+3+2 of things like the piano. These cross rhythms just make things a little more interesting. Here is what it sounds like:
download if embed doesn't work
So here is the combined version with all the instruments so far.
download if embed doesn't work
This will be the instrumental part of our verse.
It's often hard when first adding a instrument or two not to put it too loud in the mix because you are enamoured by its novelty (I'm saying this from experience). But with the tracks we've just added, it is important that they are fairly subtle. You don't want them to draw too much attention. They can still be soft but noticable in their absence. To see this, compare the final recording with the one at the top of the page. I think you'll agree there's a big difference.
In subsequent posts, we'll add the chorus, build out the song's structure and add some vocals.
All material for this project is made available under a Creative Commons BY-NC-SA license so you are free to redistribute and remix with attribution but under the same license and not commercially.
by : Created on Nov. 27, 2008 : Last modified Nov. 27, 2008 : (permalink)
Church Encoding in Python
If we define true and false with the following combinators (in Python):
TRUE = lambda a: lambda b: (a) FALSE = lambda a: lambda b: (b)
then if-then-else can be implemented simply by applying a predicate to two arguments: the then/true case and the else/false case.
For example:
(TRUE)(True)(False) == True (FALSE)(True)(False) == False
Now if we define:
AND = lambda a: lambda b: (a)(b)(a) OR = lambda a: lambda b: (a)(a)(b) NOT = lambda a: lambda b: lambda c: (a)(c)(b)
we can do boolean logic with only reference to function application.
For example:
(AND)(TRUE)(FALSE) == (FALSE)
This is a little hard to verify in Python so we can use our if-then-else trick:
(AND)(TRUE)(FALSE)(True)(False) == False
Our definition of TRUE and FALSE is known as the Church encoding of the booleans.
We can also Church-encode a pair, or cons, and define car and cdr appropriately:
CONS = lambda a: lambda b: lambda c: (c)(a)(b) CAR = lambda a: (a)(TRUE) CDR = lambda a: (a)(FALSE)
If the definitions of CAR and CDR seem odd, note that the magic is really in CONS.
(CAR)((CONS)(1)(2)) == 1 (CDR)((CONS)(1)(2)) == 2
But this means CONS makes a nice way of deferring our (True)(False) trick to "unchurch" Church-encoded booleans into Python booleans:
UNCHURCH_BOOLEAN = (CONS)(True)(False)
Now we can say:
(UNCHURCH_BOOLEAN)((NOT)(TRUE)) == False (UNCHURCH_BOOLEAN)((OR)(TRUE)(FALSE)) == True
The natural numbers can also be Church-encoded:
ZERO = FALSE SUCC = lambda a: lambda b: lambda c: (b)((a)(b)(c))
We can then define:
ONE = (SUCC)(ZERO) TWO = (SUCC)(ONE) THREE = (SUCC)(TWO) FOUR = (SUCC)(THREE)
and so on. Here's a little Python function for "churching" numbers:
def church_number(n): return SUCC(church_number(n - 1)) if n else FALSE
We can define addition, multiplication and exponentiation as follows:
PLUS = lambda a: lambda b: lambda c: lambda d: (a)(c)((b)(c)(d)) MULT = lambda a: lambda b: lambda c: (b)((a)(c)) EXP = lambda a: lambda b: (b)(a)
Of course, what would be nice is if we had an easy way to unchurch our Church-encoded numbers so we could see if these work. Well, it turns out that's easy to do:
UNCHURCH_NUMBER = lambda a: (a)(lambda b: b + 1)(0)
So
(UNCHURCH_NUMBER)(ZERO) == 0 (UNCHURCH_NUMBER)(ONE) == 1 (UNCHURCH_NUMBER)(TWO) == 2
and so on.
(UNCHURCH_NUMBER)((PLUS)(THREE)(TWO)) == 5 (UNCHURCH_NUMBER)((MULT)(THREE)(TWO)) == 6 (UNCHURCH_NUMBER)((EXP)(THREE)(TWO)) == 9
by : Created on Nov. 26, 2008 : Last modified Nov. 26, 2008 : (permalink)
On Insurance
If I offered you a 1 in 2 chance of winning $1 for 60 cents you'd probably say no. After all, the expected value is 50 cents so you're more likely to lose than win.
And yet, if I offered you a 1 in 2,000 chance of winning $1,000 for 60 cents, you might agree. The expected value is the same, but the payoff (even though far less likely) is much higher. If I offered you a 1 in 20,000 chance of winning $10,000, you might be even more like to give it a go "just in case" you win.
Lotteries and casinos rely on the fact that, even with big payoffs, things will average out in their favour.
Now consider insurance...
If there's a 1 in 2 chance an event might cost you $1, you're unlikely to take out insurance with a premium of 60 cents. However, if there's a 1 in 2,000 chance an event might cost you $1,000, you are more likely to be willing to be willing to pay a premium of 60 cents. Even if an event has only a 1 in 20,000 chance of happening, if it would cost you $10,000, you might consider paying a premium of 60 cents for insurance. If the 1 in 20,000 event would cost you $1,000,000 you might be willing to pay $60 or more in premium.
An insurance company (or even non-profit cooperative) is no going to offer you a premium less than the expected value. If there is a 1 in 20,000 chance they'll have to pay out $1,000,000 you're going to have to pay at least $50 in premiums.
The important point here is that insurance only makes sense if the likelihood of needing it is low. If the need is high, the premium will be close to the payout and, it's probably just not worth it. (Literally "probably" :-)
Insurance is about trading off an unlikely high cost for a definite low cost.
What about a situation where the event is almost certainly going to happen? In such a case, insurance is going to cost more than its worth. If it is known I'm going to have an event which will cost me $1,000, no insurance company is going to cover me for a premium less than $1,000.
And yet, people take out health insurance which covers highly probably or even certain events.
If your insurance covers an annual checkup, or new glasses every three years or a teeth clean every six months, or a regular therapy appointment: IT'S GOING TO COST MORE THAN IT'S WORTH.
In the case of predictable but not-that-frequent events, a case can definitely be made for trading off an infrequent (but likely) high cost for a frequent low cost. But this is NOT insurance. It's really just a type of amortization.
The fact that likely events get bundled in with real insurance is one of the reasons, I think, why health insurance is so expensive in the US.
POSTSCRIPT: A while ago I read about people in India who offer you insurance against the fine for riding on the train without a ticket. The cost of taking the insurance is less than the cost of the ticket, so morals aside, you're better off taking the insurance and not buying a ticket. Clearly this is a price signal that the ticket-to-fine ratio is higher than the chance of getting caught and either the ticket price should be lowered, the fine increased, or the chance of catching culprits be increased.
by : Created on Nov. 26, 2008 : Last modified Nov. 26, 2008 : (permalink)
Steele's Growing a Language is a Masterpiece
If you are at all interested in differences between programming languages and the trade offs a programming language designer must make, and if you haven't already seen it, you really must watch Growing a Language, Guy Steele's Keynote from the 1998 OOPSLA conference.
Not only is the content fascinating, but there's a wonderful twist he starts to reveal at 7:45 (through to 9:00) to do with the whole style of the presentation (which does seem odd, though humorous, at first). It's like something out of Gödel, Escher, Bach where the structure, as much as the surface content, is where the message lies.
I don't want to say too much more, lest I give things away, but the talk really is a masterpiece.
by : Created on Nov. 25, 2008 : Last modified Nov. 25, 2008 : (permalink)
First Pinax Screencast Competition
The goal is to produce a screencast up to 20 minutes long, showing what can be built with Pinax in a short amount of time.
You have 3 weeks to submit your entry or entries and then the core developers of Pinax will judge the best entries. You can submit as many times as you like.
Judging Criteria
Submissions will be judged on three criteria with certain weightings:
- the overall video and audio quality of the screencast (20%)
- how impressive the end result of what you build is (30%)
- how well it shows off Pinax (50%)
You can have some stuff developed in advance (i.e. the entire site you build doesn't have to be built in 20 minutes) but that's a tradeoff you have to make between the second and third criteria. More done in advance means probably a more impressive end result but shows off Pinax less; more you actually do during the screencast, might mean a less impressive result at the end but shows off Pinax more.
License
We require all videos to be made available under a Creative Commons Attribution-Share Alike license so we can distribute them in edited and unedited form.
Prize
The first prize is a $100 Amazon Gift Card with a runner up prize of a $40 Amazon Gift Card. Even though you can submit more than one entry, the same person won't be able to win both prizes (even if they have the 1st and 2nd best submissions).
See http://contests.pinaxproject.com/contest/3/
by : Created on Nov. 24, 2008 : Last modified Nov. 24, 2008 : (permalink)
EQ, Part I
In the previous song project post, I mentioned that the tracks had some EQ on them. There are a number of different reasons for using EQ:
- on individual instrument tracks to bring out particular characteristics of that instrument
- on individual instrument tracks to make multiple instruments sit better together
- on the overall mix to reduce listener fatigue
- on the overall mix to make up for deficiencies in the listening environment
The third is normally done at mastering stage and the fourth by both mastering engineers (preempting deficient listening environments) and the listeners themselves. I'm not going to talk about either of them here.
Here is a graph showing the frequencies coming from the particular piano sound I'm using when I play an A.

Note that the main peak is that the fundamental frequency of 440Hz. There are also bumps at multiples of 440: 880Hz, 1320Hz, 1760Hz and so on. It is the amplitude of those overtones and how they change over time that really makes the note sound like a piano and not something else. Notice that there are also other little bumps—lots is going on: from other strings resonating to the actual sound of the hammer hitting the string (as opposed to just the string vibration itself).
But typically you aren't just playing a single note. Here is the same graph for the right hand piano riff from the song:

The important thing here is just the range in which the frequencies occurs.
And here is the full piano riff, both left and right hands:

Because the piano parts are fairly high, you see there isn't much happening below 220Hz (which is A2, the lowest note the piano plays in the song).
If you compare that to the bass guitar riff:

you'll notice most of the action is happening between 55Hz and 220Hz. But notice that there are other bumps as well. Boosting in that range will change how much those other sounds with come through.
I'm still a novice at mix engineering but one thing I've definitely learnt is that you want to treat different drums separately during EQ. In particular you want to EQ your kick and snare separately.
Of course, drums aren't playing a pitch but they have a very complex set of frequencies and lots going on at different parts of the spectrum.
Here's the raw analysis of the kick drum:

Notice most of it is sub-100Hz but there is significant stuff going on above 1000Hz (other vibrations beside the skin, the initial hit sounds as opposed to the sound that reverberates in the chamber)
Here's the snare for comparison:

You can see the main frequency is around 200Hz but there are other bumps caused by things like the actually sound of the stick hitting the skin. In a subsequent post, I'll include sound samples so you can here the effect of boosting different frequencies.
In additional to controlling the sound of the individual instruments, there is also the relationship between the instruments as I mentioned at the start. In this particular song, the piano doesn't go low enough to really muddy the bass, but if it did, I might want to attenuate the low frequencies of the piano. Making sure the snare comes through is important, so I could boost it around 200-300Hz or narrowly scoop out that frequency from other instruments.
In the recordings you've heard so far, the piano does have a drop off below 200Hz (even though it doesn't really need it); the snare is boosted at 200Hz and 800Hz; the kick drum is boosted at 60Hz, 1500Hz and 3500Hz but attenuated at 200Hz; and the bass guitar is boosted at 80Hz. These are by no means final numbers; more of a default to use as a starting point.
And there's a whole other dimension to all this one vocals are added :-)
by : Created on Nov. 23, 2008 : Last modified Nov. 23, 2008 : (permalink)
Preformatting Comments that Still Wrap
For a while, it's frustrated me (and I'm sure some of my commenters) that indentation in comments is lost, particularly given the code snippets people often paste in.
I didn't want to make all comments pre-formatted so my first thought (which I implemented locally) was to add a boolean field on comments where a user could elect to have their comment pre-formatted. That would be annoying for the non-code parts of their comments, though. So my second thought (which I also implemented locally) was to have a toggle where a comment could alternatively be viewed as pre-formatted or not.
But in tweaking that I was reminded of the CSS2 property white-space. In particular, the value pre-wrap which honours multiple consecutive whitespace characters but still wraps to fit in the required width of the box. According to quirksmode.org it's not understood by FF2 or IE6/7. A value of pre might work in that case but the wrapping part of pre-wrap is really nice.
You can see it in action in the first comment of First Success With Combinatory Python (unless you are running FF2 or IE6/7).
If anyone knows of a simple fallback to pre I can do for those browsers, I would be interested in trying it.
by : Created on Nov. 23, 2008 : Last modified Nov. 23, 2008 : (permalink)
First Success With Combinatory Python
In More Questions on the Path to Combinatory Python I wondered how to write an 'add' function such that not only
(add)(2)(2) == 4
worked but also things like:
(add)(add)(1)(2)(3) == 6 (add)(1)(add)(2)(3) == 6
If we throw in a unary function like 'neg' then things like this should work too:
(neg)(5) == -5 (neg)(neg)(5) == 5 (add)(3)(neg)(2) == 1
Here's how I started to think about it. An expression such as (add)(2)(2) could be described as having the signature "200". It consists of subexpressions requiring, respectively 2, 0 and 0 arguments. Just (add)(2) would have a signature "20" which is equivalent to a signature of 1.
Using this notion:
- (add)(add)(1)(2)(3) has signature 22000
- (add)(1)(add)(2)(3) has signature 20200
- (neg)(5) has signature 10
- (neg)(neg)(5) has signature 110
- (add)(3)(neg)(2) has signature 2010
It is easy to see that for an expression to be complete (i.e. not partial) it must have a signature ending in 0. But there is slightly more to it that than. Basically, start off with a score of 1 and work from left to write, every "2" you encounter increases the score by 1 and every "0" decreases it by 1. A "1" has no effect. When you hit a score of 0 you're complete.
Every complete signature has a particular bracketing of function application. For example, expressions of signature 112100 can be evaluated as follows:
def eval112100(a, b, c, d, e, f): return a(b(c(d(e))(f)))
and each partial signature has a function that can dispatch evaluation to another function depending on the number of args the next arg takes (relying on a function like add being annotated with add.args = 2).
def eval1121(a, b, c, d): return lambda e: ( eval11210 if e.args == 0 else eval11211 if e.args == 1 else eval11212 if e.args == 2 else ... )(a, b, c, d, e)
I was still struggling to implement this in a recursive way that could handle unlimited depth and then I saw in a comment that Eric Wald came up with a solution:
def combinatoric(n): def decorator(f): @wraps(f) def wrapper(x): if callable(x): return lambda y: combinatoric(n)(f)(x(y)) elif n > 1: return combinatoric(n - 1)(wraps(f)(partial(f, x))) else: return f(x) return wrapper return decorator
and so you then say
@combinatoric(1) def neg(x): return -x
@combinatoric(2) def add(x, y): return x + y
and it all works. The use of wraps is optional but including it means partial add will have the name add not wrapper.
As Eric points out in his comment, this still doesn't solve the (add)(M)(5) issue but I have some thoughts on that for a subsequent post.
by : Created on Nov. 22, 2008 : Last modified Nov. 22, 2008 : (permalink)
Relations with Python Named Tuples
Back in 2006, I wrote an entry called Python Tuples are Not Just Constant Lists which, after the Dr Horrible covers is my most visited blog post ever.
In it, I suggest that:
the index in a tuple has an implied semantic. The point of a tuple is that the i-th slot means something specific. In other words, it's a index-based (rather than name based) datastructure.
In that same post, I pointed out the connection between the relational algebra and this notion of a tuple and further suggested that:
it might be useful to have the notion of a tuple whose slots could additionally be named and then accessed via name.
I implemented aspects of this in my initial explorations of relational python. Basically a relation in relational algebra is a set of dictionaries (called tuples) where each dictionary has identical keys (called attributes). In Basic Class for Relations, I actually use Python tuples internally but they go in and out as dictionaries. As I said in that post:
Basically, I store the each tuple internally as a Python tuple rather than a dictionary and the relation also keeps an ordered list of the attributes which is used as the index into the tuples. Amongst other things, this gets around dictionaries not being hashable. It's also a storage optimization akin to using slots for Python attributes.
Here is a slightly cleaned up version of my code at the time:
class Rel: def __init__(self, *attributes): self.attributes_ = tuple(attributes) self.tuples_ = set() def add(self, **tupdict): self.tuples_.add(tuple([tupdict[attribute] for attribute in self.attributes_])) def attributes(self): return set(self.attributes_) def tuples(self): for tup in self.tuples_: tupdict = {} for col in range(len(self.attributes_)): tupdict[self.attributes_[col]] = tup[col] yield tupdict
One could then say stuff like:
rel1 = Rel("ENO", "ENAME", "DNO", "SALARY") rel1.add(ENO="E1", ENAME="Lopez", DNO="D1", SALARY="40K") rel1.add(ENO="E2", ENAME="Cheng", DNO="D1", SALARY="42K") rel1.add(ENO="E3", ENAME="Finzi", DNO="D2", SALARY="30K")
and in subsequent posts I started to show how some relational operations could be performed on this datastructure.
Well, now in Python 2.6, some of this can be simplified. Python 2.6 introduced a wonderful new collections type called a named tuple — a tuple whose slots can also be addressed by name.
Now I can do something similar to Rel above as follows:
from collections import namedtuple class Rel: def __init__(self, typename, field_names): self.tuple_type = namedtuple(typename, field_names) self.tuples = set() def add(self, **tupdict): self.tuples.add(self.tuple_type(**tupdict)) def attributes(self): return set(self.tuple_type._fields)
and use it as follows:
rel1 = Rel("EMPLOYEE", "ENO ENAME DNO SALARY") rel1.add(ENO="E1", ENAME="Lopez", DNO="D1", SALARY="40K") rel1.add(ENO="E2", ENAME="Cheng", DNO="D1", SALARY="42K") rel1.add(ENO="E3", ENAME="Finzi", DNO="D2", SALARY="30K")
then:
>>> rel1.attributes() set(['SALARY', 'ENAME', 'DNO', 'ENO']) >>> rel1.tuples set([EMPLOYEE(ENO='E1', ENAME='Lopez', DNO='D1', SALARY='40K'), EMPLOYEE(ENO='E3', ENAME='Finzi', DNO='D2', SALARY='30K'), EMPLOYEE(ENO='E2', ENAME='Cheng', DNO='D1', SALARY='42K')]) >>> for employee in rel1.tuples: print employee.ENO, employee.ENAME E1 Lopez E3 Finzi E2 Cheng
by : Created on Nov. 21, 2008 : Last modified Nov. 21, 2008 : (permalink)
More Questions on the Path to Combinatory Python
I was just thinking yesterday that I need to get back to the posts I was intending to make after my initial post of the month, Two Fun(ctional) Questions. Then tonight Eric Florenzano made an excellent post on Lambda Calculus which is related to my topic of interest.
So let me take one of his examples and raise again the issue from my first post.
First of all, consider the following Python function taking two arguments:
>>> add_ = lambda x, y: x + y
This function works as expected:
>>> add_(5, 4) 9
Eric shows a curried version defined in Python:
>>> add = lambda x: lambda y: x + y
and shows how, when given one number, this returns a function that takes a second number and adds it to the first:
>>> add(5)(4) 9
To emphasize my desire to blur the distinction between functions and constants, I'd like to point out the following works too:
>>> (add)(5)(4) 9
But imagine we want to add three numbers. With our two-argument version, we could say:
>>> add_(5, add_(2, 2)) 9
How would we do that with our curried version? I'm NOT talking about defining a new 'add', I'm talking about using multiple applications of the original 'add' just like we did with 'add_' above.
The following works:
>>> (add)(5)((add)(2)(2)) 9
but note the additional parentheses we had to add. If we wanted to instead defer the application of the final argument we'd have to rewrite it as:
>>> (add)((add)(5)(2)) <function <lambda> at 0x755f0> >>> (add)((add)(5)(2))(2) 9
So the question is: is there a way to modify add (hopefully with just a wrapper that could be applied to any unary function) such that the following work:
(add)(5)(add)(2) (add)(5)(add)(2)(2)
where the former is equivalent to (add)(7) and the latter returns 9?
And is this pretty much the same question I asked in my original post with the very same solution(s)?
By the way, here is another example that should work in any true solution...
If I define
>>> M = lambda x: (x)(x)
then we should be able to get
(add)(M)(1)
to return 2.
Or is this whole hybrid approach destined to failure and the only real way to use combinators is with Church-encoded numerals?
by : Created on Nov. 20, 2008 : Last modified Nov. 20, 2008 : (permalink)
Post Length By Month
I made the comment in my Half Time Report that I think I've managed to stick to "posts no shorter than normal and no longer".
Alas the data don't match that.
Here's a graph of average post length (just len(page.content.split())) by month:

Clearly the posts this month are longer on average. And because I'm writing more of them, the last point of this next graph is no surprise.
This is a graph with post lengths totalled for each month:

And obviously this month has a fair bit to go. What's more interesting though is my first year of blogging saw growth in total words posted per month grow to a peak around 7500 in December 2004 and then a clear trend down to the trough in August 2006 when I posted just 3 short posts the whole month.
These graphs were done with IBM's Many Eyes simply because Apple Numbers fails miserably at charting anything but the smallest data sets.
by : Created on Nov. 20, 2008 : Last modified Nov. 20, 2008 : (permalink)
The Long and Short of Mathematics
I've previously talked about Oxford's Very Short Introduction series. My first introduction to it (via a recommendation from Greg Mankiw) was Timothy Gowers' Mathematics: A Very Short Introduction which is the best little (160 page) book I've ever read on what mathematics is really about.
A few weeks ago, I bought The Princeton Companion to Mathematics which weighs in at 1008 pages. It's sweeping vista of pure mathematics, and probably the best big book I've ever read on pure mathematics in general. It provides survey articles on many different areas within pure mathematics from both a conceptual and historical viewpoint. I would say most of the book requires some college-level background in mathematics and some sections would best suit graduate students (although to give them breadth rather than depth) but it's the kind of book that you can dive in to at any point and learn something.
So it's interested that the editor of the PCM is the same Timothy Gowers that wrote the Oxford Very Short Introduction.
Well done, Professor Gower. You have succeeded in producing what I think are the best small and large single volume books on mathematics.
Just like in Greek Lexicography we have the "Little Liddell", "Middle Liddell" and "Big Liddell" (referring to the abridged, intermediate and full versions of Liddell and Scott's A Greek-English Lexicon) I think these books should be known as "Little Gowers" and "Big Gowers" :-)
by : Created on Nov. 19, 2008 : Last modified Nov. 19, 2008 : (permalink)
Discrete Cosine Transforms Part 1
I've often been intrigued by the lossy part of JPEG compression so I thought I'd explore Discrete Cosine Transforms and their use in JPEG as a short multi-part blog series.
In this part, lets just talk about what a "discrete cosine" function is and then in the next couple of posts look at how the concept can be combined with basic linear algebra to break up images into components in such a way that you can throw out some components with minimal effect on the perceived image. It's quite clever but the mathematics is fairly straightforward.
Let's start with a single cycle of a cosine function shifted up and scaled so its values range from 0-255 instead of from -1 to +1. To make it discrete, we'll divide it up into four and simply take the value of the scaled cosine function at the midpoint of each of our four sections:

Here our four discrete values are 217, 39, 39, 217 .
Now let's do the same for one and a half cycles:

which yields values of 176, 11, 245 and 80.
Now half a cycle:

which yields 245, 176, 80 and 11 and zero cycles:

which gives us 255, 255, 255, 255
We've basically calculated values for 0 thru 3 half cycles. If we wanted to split the cosine into N pieces instead of 4, we'd calculate values for 0 thru N-1 half cycles.
But, in summary, for N = 4:
- k = 3: 176, 11, 245, 80
- k = 2: 217, 39, 39, 217
- k = 1: 245, 176, 80, 11
- k = 0: 255, 255, 255, 255
by : Created on Nov. 18, 2008 : Last modified Nov. 19, 2008 : (permalink)
Fixing Relative Links In Entries
Occasionally I hear from someone who finds the links in my entries are broken in their feed reader, especially if they are reading a syndicated version of my entries.
The reason is that I have relative links which are not being made absolute by the reader (or syndication code).
Many readers (such as Google Reader) treat relative links as being relative to the feed itself, so /blog/ gets converted to http://jtauber.com/blog/. But even if the reader does, this, that doesn't help with syndicated entries unless the syndicator does some processing. Some do but others don't.
There's nothing wrong with relative links in Atom content, but if you use them you really should have an xml:base attribute to help a reader deal with them properly. I've now updated all my entries to include an xml:base. I'll see how many planets and other syndications pass that through when placed on the entry. I wonder if the content element would be better.
In the process of making the change, though, I noticed my entry/link[@rel="alternative"] were also relative which is, I suspect, a no no. So I've made them absolute as well.
I'm going to do a little bit more experimentation, but things should work now. I may still have goofed up somewhere but I'm fairly confident now that if links are broken then it's either a bad reader or bad syndication involved. Either way, please let me know in a comment below if you encounter any problems here on in.
UPDATE 1: The atom feed of the unofficial planet python doesn't pass through the xml:base but it doesn't need to as it has made all links absolute (and was doing so before my change)
UPDATE 2: I'm afraid that Advogato's syndication is just plain broken. In their RSS 2.0 feed (why not provide Atom!?), they make content links absolute but they do so by treating them relative to www.advogato.org !! My only suggestion is to just avoid Advogato syndication all together. I'm tempted to turn it off.
by : Created on Nov. 17, 2008 : Last modified Nov. 17, 2008 : (permalink)
Context Hierarchies in OmniFocus
I'm giving OmniFocus another chance after I found it didn't stick after I was a beta tester. I actually switched to Things for a while but that didn't stick either. Anyway, that's not actually what I wanted to blog about.
I want to talk about the use of hierarchy in contexts because I've just been reminded of one confusion I had during the beta. I should point out up front, this isn't really intended as a dig at OmniFocus specifically, more a general reflection on the nature of hierarchy and containment versus subsumption. Still with me?
OmniFocus supports GTD-style contexts such as @Online and @Email and also lets you group those contexts into a hierarchy so @Online and @Email can both be under a parent context @Computer.
As one might expect, the parent context subsumes its children. If you are @Online then you must also be @Computer, but you may be @Computer but not @Online (say while on a plane).
In light of this, the behaviour of OmniFocus is odd and almost the complete opposite of what one might expect (or want).
If you put an action in @Online it will appear not only when you set your current context to be @Online but also when you set your context to the more general @Computer. And if you put an action in @Computer, it will only appear if you are @Computer and not if you select the more specific @Online.
To me, this is completely backward. If I am @Online (and, by implication, therefore @Computer) then really I should have available to me @Computer actions as well as @Online actions. Similarly, if I wish to state I am @Computer (and therefore am either not @Online or am leaving whether or not I am unspecified) then I would not want to see those actions that require me specifically to be @Online.
The only conclusion one can draw is that the hierarchy of context in OmniFocus (or other similarly behaving GTD apps) is not about subsumption at all. If you make @A a parent of @B you are not in fact saying that @B implies @A or that @B is a special case of @A. If you use the hierarchy with that implication, it won't work at all. Instead, I think all you are saying is that @A is just a grouping of @B and other contexts you might, from time to time, want to look at together, and not a real context in its own right.
Of course, if you really want to model subsumption, you need a lattice, not a tree.
by : Created on Nov. 17, 2008 : Last modified Nov. 17, 2008 : (permalink)
Half Time Report
We're just over half way through the month so I'd thought I'd give a quick review of how blogging month is going.
First of all, I've successfully written every day and I think I've managed to stick to the sort of stuff I would have blogged about anyway—posts no shorter than normal and no longer.
I've actually written 25 posts (not counting this one) which is appropriate given that the NaNoWriMo folks should be at 25,000 words around now.
At some point, I'll actually do a word count which should be pretty easy in Django :-)
by : Created on Nov. 16, 2008 : Last modified Nov. 16, 2008 : (permalink)
Song Project: Adding Bass and Drums
Let's take the piano riff I previously wrote and add a bass line. This was entirely improvised but you'll hear it's very rhythmically similar to the left-hand of the piano part, even down to the 3+3+2 accents except in the third bar of four where 3+2+3 is suggested.
download if embed doesn't work
And now let's add the drums. I took a standard kick, snare and high-hat pattern that comes with Logic Pro and modified it to give a machine-gun rhythmic interplay between both high-hat and kick drum.
download if embed doesn't work
While the interplay between kick and high-hat makes for an interesting rhythm, we'll eventually want to vary it subtly throughout the song to keep things more interesting. We'll worry about that later, though.
Here's a combined version with piano, bass and drums:
download if embed doesn't work
Note that all tracks had some compression and EQ. In a later post I'll talk a bit about that.
Then we'll add a few more tracks before moving on to composing the chorus, putting together the overall song structure and, of course, adding the vocals.
All material for this project is made available under a Creative Commons BY-NC-SA license so you are free to redistribute and remix with attribution but under the same license and not commercially.
by : Created on Nov. 16, 2008 : Last modified Nov. 16, 2008 : (permalink)
Category Feeds Available
I finally got around to doing something I've wanted to do for ages, only to discover it could be done in all of fifteen minutes. I'm talking about per-category feeds on jtauber.com
For over a year, my django-atompub has supported the parameterized feeds that django's built-in syndication feeds do but I never made use of them myself.
Fifteen minutes and roughly 20 lines of code later, the site now has a separate feed for each category. If you go to a page that is also a category, such as python or django or music theory or filmmaking or poincare project there will both be an extra feed advertised in the html head and a link from the "feed icon" after the list of "Pages in this category". So if you are only interested in a particular topic you can just subscribe to that (although I hope you don't—I did this more for topical aggregators)
One thing I always struggled with when thinking about category feeds before was how to handle subsumption relationships. If I put something in django should it automatically go in python? If in python then in some broader software category? or computing category? I certainly want to avoid the assumption of hierarchy (see some previous posts on that topic).
So for now I've left categories with no additional structure.
by : Created on Nov. 15, 2008 : Last modified Nov. 15, 2008 : (permalink)
Getting Xcode to Work on Mac OS X 10.5.5
This morning I tried to start up Xcode but it crashed on startup.
The console revealed:
layout bitmap too short: ASKScriptView
After a bit of searching I found this blog post. Although the main post wasn't quite relevant, one of the commenters described my problem:
Xcode 3.1 has been crashing for me since the 10.5.5 update with an error saying "layout bitmap too short: ASKScriptView". I couldn't find reference to this online and was completely stumped.
Another commenter said:
just get the '/usr/lib/libobjc.A.dylib' from a 10.5.4 system (Look for it in a 10.5.4 combo updater file) and swap it with the newer version. Then, it works again.
So I searched on Apple's site for the Mac OS X 10.5.4 Combo Update.
But then I was stuck with a 561MB .pkg I just needed extract one file from and I had no idea.
More searching revealed the shareware Pacifist from CharlesSoft which I promptly downloaded. It worked like a charm and let me extract just the libobjc.A.dylib I needed.
Now Xcode starts up fine! Sending my $20 in to Charles...
by : Created on Nov. 14, 2008 : Last modified Nov. 14, 2008 : (permalink)
RED Changes the Game Again
Back in 2005, I talked about the vague announcement of an upcoming a 2540p camera based on a full frame 4K CMOS from a company founded by the founder of Oakley. The camera, RED ONE, was launched in 2007 and was viewed by many as a game changer in digital cinematography.
Now RED is changing the game again. They've just announced a new modular system that separates out the sensor, lens mount, I/O, recording module, battery, viewfinder, remote, etc all as separate components you can mix and match. They also announced a line of sensor modules (what they call 'brains') that I'll talk about in a moment.
I'm blown away just like I was in 2005 and there is some nice tech pr0n at http://www.red.com/epic_scarlet/ for you to look at to see what I'm talking about.
In addition to the modular approach, which I find very compelling, the other thing that blew me away is a couple of the 'brains' they offer and their sensors.
I've talked about sensor sizes before. Most consumer video cameras have 1/3" sensors. Professional video cameras are generally 2/3". Even Star Wars Episode II was shot on 2/3" cameras capable of 1080-line resolution. Remember the 1920x1080 is 2 megapixels. Video was a fair way behind digital still cameras, which was why the announcement from RED back 2005 was so tantalizing. A typical DSLR has an APS-C sized sensor (or similar).
But look what RED has done now. They have sensors designated S35, FF35, 645 (medium format) and 617 (large format panoramic). I've shown all the sensors sized I've mentioned below for comparison (done in the same scale and style as my previous post on sensor sizes). Yes, that huge rectangle is (roughly, depending on your screen resolution) the sensor dimensions in actual size.
The full-frame FF35 is 24MP. So it's already as good as any professional DSLR and it can shoot video up to 100fps!!
The 645 is 56mm x 42mm and 65MP. The 617 is...wait for it...186mm x 56mm with 261MP. And both these shoot video at 50fps and 25fps respectively.
Finally, the dynamic range on the FF35, 645 and 617 are supposedly 13+ stops. That is incredible (although admittedly the larger pixels sizes of such large sensors make that possible)

Simply mind blowing!
by : Created on Nov. 13, 2008 : Last modified Nov. 13, 2008 : (permalink)
Book Meme
Too slow a tempo is unsuitable to the ornamental melodic motions characteristic of the third species.
from Counterpoint in Composition by Felix Salzer and Carl Schachter
Meme from Greg Newman, Justin Lilly and Brian Rosner:
- Grab the nearest book.
- Open it to page 56.
- Find the fifth sentence.
- Post the text of the sentence in your journal along with these instructions.
- Don't dig for your favorite book, the cool book, or the intellectual one: pick the CLOSEST.
by : Created on Nov. 12, 2008 : Last modified Nov. 12, 2008 : (permalink)
X will cost Y jobs
One type of clause that I have long had an issue with is that of the form
X will create Y jobs
which I most recently read in descriptions of the newly passed proposition for a high-speed rail project in California (which will, supposedly, create 450,000 jobs)
The problem is the assumption that job creation is a benefit. The benefit of the high-speed rail project is presumably supposed to be energy-efficient transportation that will reduce greenhouse gases. I'm all for that. But if you can achieve that with 350,000 jobs that's actually better than taking 450,000 jobs to do it.
Say two start ups are founded and one can build the product with 10 people and another will take 20 people to do the same thing. It seems crazy to say "well the second company is creating 10 extra jobs". No, the second company is wasting 10 jobs. Those people could be doing something more productive (either within the company or somewhere else).
And that gets to the heart of the matter. Creating jobs means taking people away from doing something else.
"What about helping unemployment?" you ask.
What are the chances that the 450,000 people that will work on the California rail project, will all otherwise be unemployed? Pretty slim. Now, to the extent that otherwise unproductive people are made productive (and are paid accordingly) then that is definitely a benefit.
Who knows, maybe all 450,000 people will be doing something more productive than they otherwise would have been doing. But the articles don't say "X will employ Y people more productively", they just say "X will create Y jobs" which, taken as is, is a cost, not a benefit.
I've suggested before that many precepts in economics come down to the concept of opportunity cost. This one is no different.
And, of course, this is all just economics 101. Go read Hazlitt's classic Economics in One Lesson. There's a nice treatment of the "make-work bias" in Bryan Caplan's excellent The Myth of the Rational Voter.
Let me finish with a classic story:
An economist visits China under Mao Ze dong. He sees hundreds of workers building a dam with shovels. He asks: 'Why don't they use a mechanical digger?''That would put people out of work,' replies the foreman. 'Oh,' says the economist, 'I thought you were making a dam. If it's jobs you want, take away their shovels and give them spoons.'
UPDATE: I actually preferred how I explain somethings in a comment below in response to a question so I thought I'd bump up my response into the main body:
whether diverting those 10 people to that startup is a good thing ultimately depends if the start up produces something worth that diversion. It is not prima facie a good thing just because it's using up 10 people. Similarly, the diversion of 450K people to build a high-speed train system may be a good thing (and hopefully will be) but would not be because it diverted 450K people, it would be that despite the fact it diverted 450K away from other things, it was still worth it for the benefit of having the train system.
by : Created on Nov. 12, 2008 : Last modified Nov. 12, 2008 : (permalink)
Storing HTTP_X_FORWARDED_FOR in Django
I occasionally get a
ProgrammingError: value too long for type character(15)
when people post to my blog. There aren't any fields in my model declared to have a max_length of 15 so I was always a little confused and in almost all cases, it was a spammer anyway so never took the time to investigate further.
But then someone just emailed me and told me they were getting a 500 when posting a comment to my blog. So I decided to investigate and that's where it started getting interesting...
Doing
./manage.py sql leonardo
revealed no sign of a field of length 15 either. So I went into the DB (in my case PostgreSQL)'s shell.
A quick
\d leonardo_comment
revealed
author_ipaddress | character(15)
Like many blogs, I capture the IP address of the commenter so I can block spam.
In my model I have:
author_ipaddress = models.IPAddressField(null=True)
Which Django's ORM translates to:
"author_ipaddress" inet NULL
which PostgreSQL is obviously storing as a character(15).
Why would an IP Address be more than 15 characters, though?
Well, I went back to the error log and noticed this:
'HTTP_X_FORWARDED_FOR': '192.168.0.127, 12.34.56.78',
(note: I changed the second address to protect the original poster)
You see, because the Apache instance running django is behind another webserver (on the same machine), I can't rely on REMOTE_ADDR because it's always 127.0.0.1. So I log HTTP_X_FORWARDED_FOR.
What I didn't realise until now is that HTTP_X_FORWARDED_FOR can be a list.
I guess the best solution is to just change the field to a CharField.
Other Djangonauts who are logging HTTP_X_FORWARDED_FOR might want to heed this warning: don't use IPAddressField.
by : Created on Nov. 11, 2008 : Last modified Nov. 11, 2008 : (permalink)
Chrome Overtakes IE
I was just looking at the analytics for http://pinaxproject.com/ and noticed the following browser stats for the last month:
Firefox 68.79% Safari 13.84% Chrome 5.88% Internet Explorer 4.31% Opera 3.26%
What stood out to me is that more people have accessed the website using Chrome than IE!
by : Created on Nov. 10, 2008 : Last modified Nov. 10, 2008 : (permalink)
You Need More Than Equipment to be a Cinematographer
With its full frame 1080p video, I've seen a bunch of articles like this one that claim "The Canon 5D Mk II Will Turn Us All Into Professional Cinematographers".
Yes, the 5D Mk II, with a full-frame sensor and EOS lens system is potentially a game changer, but to suggest that we'll all be able to produce results like professional cinematographers is stretching it.
While a good understanding of photography helps with cinematography, it's necessary but not sufficient knowledge.
- composition is important but you also need to know how to move the camera during a shot
- you also need to understand concepts like "crossing the line"
- with the narrow depth of field full-frame affords, you need to be able to pull focus while shooting—that's a whole new skill to learn (and you probably need to use a follow focus)
- you can't rely on shutter speed or aperture to control exposure the same way you do with still photography—you have to learn to rely more on ND filters and lighting
- colour correction becomes even more important as mismatches are more jarring
I hope that the Canon 5D Mk II will encourage people to learn more about the art and craft of cinematography. But the equipment is not the end of the story, it's just the beginning.
by : Created on Nov. 10, 2008 : Last modified Nov. 10, 2008 : (permalink)
Groups, Tribes and Projects in Pinax
From fairly early on, Pinax had tribes and projects. The intention of the distinction was that tribes are a loose grouping of people with a common interest (see Seth Godin's great little book Tribes: We Need You to Lead Us) whereas projects were more focused around managing a group of people working on common tasks.
This distinction was reflected in the differences in implementation: projects are invite only, tribes are open to anyone. Projects have tasks, tribes don't. But there are a lot of similarities: both have threaded discussion, wikis and photo pools. There's also a lot of duplicated code.
It wasn't long before I realised that really projects and tribes we just two subclasses of the same class (or instances of the same metaclass—more on that in a moment). So one of the things we're working on for the next release of Pinax is to merge the two into a single model but then allow a site developer to create as many differently configured subclasses/instances of this model as they like.
We haven't worked out the details yet, but basically it would allow you to define a new subclass/instance of "group", pick the membership model and what apps and object types can be attached to it.
Quite separately, I've noticed that there is another kind of structure that tacitly exists between tribes on Cloud27. I started a Python tribe but others have started Ruby and PHP tribes. There are also geographic tribes and language-based tribes. So there is another sense in which a set of tribes could be labelled as "programming language" tribes, or "geographical" tribes or "natural language" tribes.
So we have:
- the root group type (that will unify projects and tribes)
- types of groups (e.g. projects, tribes, other combinations of features and membership patterns defined by site developers)
- instances of one of these types (e.g. a particular tribe, like 'Python')
- a category of instances (e.g. 'Programming Language Tribes')
To slightly complicate things, one could imagine an "Australian Pythonistas" tribe. Or various intersections of "movies", "food", etc with geography-based tribes (e.g. Italian Food, French Films). These sorts of semantic relationships seems quite orthogonal to defining a type of group that has a wiki but not threaded discussions or is invitation-only versus free-for-all.
I'm trying to wrap my head around which to view as instances versus subclasses. As a longtime data modeler, I thought I had a grasp on this stuff but my brain is hurting :-)
Any suggestions for a metamodel?
by : Created on Nov. 9, 2008 : Last modified Nov. 10, 2008 : (permalink)
From Focus and Directrix to Bézier Curve Parameters
For reasons that will become clear in a couple of posts, I wanted to be able to calculate quadratic Bézier curve parameters from a focus and horizontal directrix.
A focus and directrix are enough to define a parabola (in fact a parabola is the locus of points equidistance from a point, the focus, and a line, the directrix).
A quadratic Bézier curve is a section of a parabola and is defined by three points, according to the formula:
B(t) = (1-t)²P₀ + 2t(1-t)P₁ + t²P₂, t ∈ [0, 1]
Here's how I came to my result...
Given the directrix is horizontal,
- P₁ must have the same x-coordinate as focus
- P₁ must have an x-coordinate midway between P₀ and P₂
and by definition:
- the parabola's low point is midway between the focus and directrix
Now even though somewhat arbitrary and assuming the directrix is below the focus,
- P₀ and P₂ can have a y-coordinate of 0
So,
- the parabola's low point's y-coordinate is midway between P₀y and P₁y
- ⇒ the y-coordinate midway between focus and directrix is midway between P₀y and P₁y
- ⇒ the y-coordinate midway between focus and directrix is half P₁y
Therefore,
- P₀ = (Fx - α, 0)
- P₁ = (Fx, Fy + Dy)
- P₂ = (Fx + α, 0)
for some α where (Fx, Fy) is focus and Dy is y-coordinate of directrix.
By definition,
- P₀ must be equidistant between focus and directrix
- P₂ must be equidistant between focus and directrix
But, given P₀ and P₂ have a y-coordinate of 0 and directrix is horizontal,
- distance between P₀ and focus = Dy
- distance between P₂ and focus = Dy
Therefore,
- (P₀x - Fx)² + (P₀y - Fy)² = Dy²
- ⇒ ((Fx-α) - Fx)² + (0 - Fy)² = Dy²
- ⇒ (-α)² + (-Fy)² = Dy²
- ⇒ α² + Fy² = Dy²
- ⇒ α = √(Dy²-Fy²)
And so, assuming the directrix is horizontal and below the focus, the following Bézier curve parameters can also be used to create the parabola:
- α = √(Dy²-Fy²)
- P₀ = (Fx - α, 0)
- P₁ = (Fx, Fy + Dy)
- P₂ = (Fx + α, 0)
UPDATE (2008-11-29): Now see Voronoi Canvas Tutorial, Part III for the motivation for wanting to do this as well as an implementation in Javascript for drawing parabolae in a canvas element.
by : Created on Nov. 8, 2008 : Last modified Nov. 29, 2008 : (permalink)
Song Project: LH Piano Riff
Having introduced the right hand of the main piano riff, let's introduce the left hand.
Firstly, here's what it sounds like by itself:
download if embed doesn't work
And together with the right hand:
download if embed doesn't work
And here's what it looks like in the score:

Now let's analyze it a little. Note that this is post hoc analysis, I didn't go through this thinking when I wrote it (at least not consciously)—it was improvised at the piano—but I find it interesting to go back and see why things worked or generated the particular effect they have.
One thing that immediately stands out is that the 3+3+2 rhythmic grouping found in the right hand is also found here (with one exception we'll come to in a minute). Also, if you look at what note is playing at the start of each of the 3+3+2 grouping: A A C♯ | D D D | B♭ B♭ - | F C E it is always the root of the current chord on the first two beats and either the root, the third or nothing on the final beat.
In the first bar, there is an additional passing note, B (notice it's natural despite the key, because the chord is A) and the C♯ is the leading note into the D chord in the next bar. The slur emphasizes this role.
In the second bar, the E is just a neighbour note between two repetitions of the root D. The final, non-accented A is in the triad of the chord but it's also the leading note of the following B♭ chord and again leading note is slurred.
In the fourth bar, the first E and D are just passing notes taking us from the F root to the C root. The final E is the third of the chord, the 5th of the A chord we return to if we repeat but it's also the leading note of the tonic F (which we'll take advantage of later). It's a great example of a note playing multiple functions both in terms of the current chord and what may follow.
The third bar (which I deliberately left until last to discuss) is a little unusual. If you imagine the second B♭ an octave higher, it's a little easier to see what's going on. In that case, the A and G are just passing notes down to the F in the next bar. But what is a little unusual is firstly that the A and G are not following the 3+3+2 pattern. It is almost as if the pattern has switched to 3+2+3 this bar. Secondly the A is quite dissonant, especially given it's only a semitone away from a note being played in the right hand. This rhythmic change coupled with the dissonance builds a nice tension that is then resolved with what I called a "triumphant" chord in a comment on the previous post.
You may notice a bit of chorusing in the piano sound of the recordings so far. Actually, there's some compression, chorusing and EQ on them, all preempting the mixing that is to follow once we add more instruments. I'll talk about each of these once we've added a few more tracks.
All material for this project is made available under a Creative Commons BY-NC-SA license so you are free to redistribute and remix with attribution but under the same license and not commercially.
by : Created on Nov. 8, 2008 : Last modified Nov. 8, 2008 : (permalink)
Voronoi Diagrams
Back in Creating Gradients Programmatically in Python I presented some code for writing out PNGs according to some rgb-function of x and y.
The relevant write_png(filename, width, height, rgb_func) is here:
http://jtauber.com/2008/11/png.py
This enables one to quickly generate PNGs based on all sorts of functions of position.
For example, here's a Voronoi diagram:

Take any metric space and pick a discrete number of points in that space we'll designate "control points" (the black dots in the above example). Now colour each other point in the space based on which control point is closest. In other words, two points are the same colour if and only if they have the same "closest control point".
Here's how to generate such a diagram using write_png...
First of all, here's a function that given an (x, y) coordinate and a list of control points, returns a pair of:
- which control point is the closest to (x, y)
- what the distance was
def closest(x, y, control_points): closest = None distance = None for i, pt in enumerate(control_points): px, py = pt d = ((px - x) ** 2 + (py - y) ** 2) if d == 0: return i, 0 if d < distance or not distance: closest = i distance = d return closest, distance
Now we can use this and write_png to generate a PNG Voronoi diagram for a given set of control points:
def voronoi(filename, size, control_points): def f(x, y): c, d = closest(x, y, control_points) # draw points in black if d < 5: return 0, 0, 0 px, py = control_points[c] # just one way to generate a colour m = px * 255 / size n = py * 255 / size return m, 255 - ((m + n) / 2), n write_png(filename, size, size, f)
Of course, this is just a brute-force way of establishing the Voronoi diagram, but for just generating examples a few hundred points by a few hundred points, it's Good Enough.
Note the choice of colouring, based on the coordinates of the control point is just one of many possibilities. You could also just colour based on control_point number (i.e. c) The current approach has one disadvantage that two control points very close to one another can be given almost indistinguishable colours.
The example diagram was just randomly generated with the following code:
import random from voronoi import voronoi space_size = 200 num_control = 8 control_points = [] for i in range(num_control): x = random.randrange(space_size) y = random.randrange(space_size) control_points.append((x, y)) voronoi("voronoi.png", space_size, control_points)
You can read more about Voronoi diagrams on Wikipedia.
by : Created on Nov. 7, 2008 : Last modified Nov. 7, 2008 : (permalink)
Song Project: RH Piano Riff
Most of my pop song ideas begin with either a chord progression voiced a particular way on piano or some bass line. The song we'll be talking about here falls in to the first category.
I remember when I first started composing in high school, I did a lot of songs that were just permutations of I, IV, V and vi chords (so in C, that would be C, F, G and Am).
I remember one instrumental I wrote in Year 10 (called "Mystical Movements in Green")—that my drama class choreographed a dance to—used the chord progression vi IV I V and in particular was voiced with the vi and I in the second inversion. I always liked the way it sounded.
A couple of weeks ago, I was improvising on my digital piano and took a liking to the following variation:
III . vi . IV . I V
with the vi and I again in the second inversion. I was playing in F at the time with a driving 3+3+2 rhythm in the right hand, so the resultant riff was:

which sounds something like this:
download if embed doesn't work
This will form the basis for the song.
All material for this project is made available under a Creative Commons BY-NC-SA license so you are free to redistribute and remix with attribution but under the same license and not commercially.
by : Created on Nov. 6, 2008 : Last modified Nov. 6, 2008 : (permalink)
Song Project
One series I thought would be fun to kick off this month is to talk about music composition and record producing and engineering by working through a song. I've chosen a song I just started working on last month and the idea is I'll go through the process from initial idea to final produced song over a series of blog entries.
All material for this project is made available under a Creative Commons BY-NC-SA license so you are free to redistribute and remix with attribution but under the same license and not commercially.
I'll get started with the music in a separate post right away.
by : Created on Nov. 6, 2008 : Last modified Nov. 6, 2008 : (permalink)
Atom, Google Reader and Duplicates on Planets
For a while I've wondered why posts syndicated across multiple planets don't get picked up by Google Reader as duplicates (and automatically marked read when I've read it the first time around).
I wasn't sure whether the problem was:
- the source feeds
- the planet feeds
- Google Reader itself
so I decided to investigate further with my own feed as the source and the three planets my site is syndicated to (that I know of).
Let's take my post Cleese and Disk Images.
My feed gives both an id and a link for both the feed itself and each individual entry. That makes it possible, at least, for planets and readers to do the Right Thing. So I don't think the problem is my feed.
On the Official Planet Python:
- there is an RSS 1.0 feed
- the rdf:about is not the same as the id in my feed but is the link URL (subtlety different but the planet is doing the wrong thing, IMHO)
- there is no authorship or source information
On both the Unofficial Planet Python and on Sam Ruby's Planet Intertwingly:
- there is an Atom feed
- the entry Cleese and Disk Images has the same id as in my feed and a distinct link.
- the source element gives appropriate information about my blog and the original feed
- the author (which I only give on the source feed not each entry) is not inherited on to the entry in the planet feed, only included in the source
Note that the handling of the author by the latter two feeds is correct per the Atom RFC, although I have noticed that Safari's feed reader gets this wrong and, despite the author in the source element, uses the inherited author from the planet feed itself.
But, in short, the Atom-feed-based Planets do the Right Thing, although IMHO the RSS-1.0-based Official Planet Python does not. That may not be the Planet's fault. The RSS 1.0 Spec (or any RSS for that matter) may not make the distinction between id and link.
So given that my feed and two of the planet feeds do the right thing, I guess that places the blame with Google Reader.
Why does Google Reader not honour the entry id and automatically mark duplicates as already read when you've read it the first time. That's my pony request for Google Reader.
And by the way, the same thing applies to feeds themselves, not just entries. Feedburner, for example, does the right thing and passes through the id of a source Atom feed into its own Atom feed version. However, if you subscribe to both the source and Feedburner version of of a feed, Google Reader doesn't not identify them as the same feed. Of course, if either are RSS, I'd assume all bets are off.
So, in summary, Atom supports doing the Right Thing. The Atom-based Planets do the Right Thing. Google Reader doesn't take advantage of this.
by : Created on Nov. 6, 2008 : Last modified Nov. 6, 2008 : (permalink)
Dear America
I'm glad you have elected someone you think brings hope and change. I hope he turns out to be one of the truly great presidents.
However, after the last eight years, you need a strong dose of fiscal conservatism. I hope your choice turns out to be the right one for that. I am not yet convinced.
by : Created on Nov. 5, 2008 : Last modified Nov. 5, 2008 : (permalink)
Cleese and Disk Images
Previously I talked about setting up a toolchain to compile i386-elf binaries for hobby OS writing on Mac OS X.
The next step in getting Cleese development working on Mac OS X was working how to build disk images for VMware Fusion for a "hello world" kernel. I got about half way over the weekend, but Brian Rosner worked out the rest Monday night.
VMware can mount a normal disk image as a floppy but can't do the same for hard drives. Turns out, though, you can create floppy images larger than 1.44MB (although I don't know if there's an upper limit).
Here's the make target Brian came up with:
cleese.img: KERNEL.BIN hdiutil create -size 5M -fs "MS-DOS" -layout NONE cleese mv cleese.dmg cleese.img mkdir -p mnt mount_msdos -o nosync `hdid -nomount cleese.img` ./mnt cp -r boot KERNEL.BIN ./mnt umount -f ./mnt rm -r ./mnt
This creates a 5MB disk image, mounts it and copies the "boot" directory from GRUB and our kernel KERNEL.BIN on to the image.
This image isn't bootable by VMware yet. You need to boot off another floppy that has GRUB and is bootable but this is a one off operation. You can easily create a bootable GRUB disk with just
cat boot/grub/stage1 boot/grub/stage2 > grub.img
Once you've booted to the GRUB command line, you can switch to cleese.img as your floppy and type
setup (fd0)
and that will copy GRUB onto the boot sector. From that point on, cleese.img is all you need.
To avoid having to do that step every time KERNEL.BIN updates, I wrote an additional make target that just updates KERNEL.BIN on an existing image.
update-image: mkdir -p mnt mount_msdos -o nosync `hdid -nomount cleese.img` ./mnt cp KERNEL.BIN ./mnt umount -f ./mnt rm -r ./mnt
As a quick guide to what that's doing:
- the -p option to mkdir just stops it complaining if mnt already exists
- hdid -nomount cleese.img binds the disk image to a /dev and returns the device path
- that device path is then used as an argument to mount_msdos (hence the backticks) which mounts that device as ./mnt
- the file(s) are copied on, the image unmounted and the mount point deleted
I'm not sure why the -o nosync is needed. Maybe it isn't.
In the original target, the -layout NONE option to hdiutil ensures no partition map is created for the drive.
by : Created on Nov. 5, 2008 : Last modified Nov. 5, 2008 : (permalink)
Daylight Saving Time
Yesterday I was asked at work what the origins of daylight savings were. People who know me know I can never just say "I don't know" to a question like that—I had to go do some research.
The short answer is "war and golf" but here is a longer version, gleaned from various articles online and a little prior knowledge on the topic.
While Benjamin Franklin is sometimes credited with the idea of setting clocks differently in the summer, his idea was well before its time as there wasn't a notion of standard time in his day. The notion that clocks would be set according to the "real time" (i.e. based on the Sun) of some other location has its origin with the railroad system. In November 1840, the Great Western Railway in England adopted London Time for all their schedules. The US and Canada followed suit with their own Standard Time in November 1883.
While Standard Time was initially for the railroads, it began to be adopted across the board, eventually being enacted into law in the US by the Standard Time Act of 1918.
An Englishman, William Willet made the observation, a century after Ben Franklin had done the same, that people were wasting the early hours of the day in summer by sleeping in. He was also an avid golfer who was frustrated at dusk cutting short his game. So he started campaigning for clocks to be advanced during the summer months. The idea was ridiculed and he died in 1915 without seeing his idea adopted.
In April 1916, however, Germany started advancing the clock an hour to reduce electricity usage and hence fuel consumption during the war. Many European countries immediately followed suit and Britain started in May 1916. When the US joined the war, they too adopted this daylight saving measure.
US Congress repealed the law in 1919, but Woodrow Wilson (incidentally also an avid golfer) vetoed the repeal. Congress overrode the veto and so daylight saving stopped, although was adopted locally in some places.
In World War II, it was reintroduced, this time all year around. The US had daylight saving from February 1942 to September 1945. After the war, it went back to being a local issue.
It was a controversial issue through the early 1960s but the confusion caused by so many local differences resulted in the US passing the Universal Time Act in 1966 which reintroduced it across the country unless overridden by state law.
My own home state of Western Australia is currently in a three-year trial of daylight saving and will hold a vote next year as to whether to keep it.
by : Created on Nov. 4, 2008 : Last modified Nov. 4, 2008 : (permalink)
Python's re.DEBUG Flag
Eric Holscher points out a Python gem I never knew about. If you pass in the number 128 (or, as I have a preference for flags in hex, 0x80) as the second arg to re.compile, it prints out the parse tree of the regex:
>>> import re >>> pattern = re.compile("a+b*\s\w?", 0x80) max_repeat 1 65535 literal 97 max_repeat 0 65535 literal 98 in category category_space max_repeat 0 1 in category category_word
While re.compile is documented as having the signature
compile(pattern[, flags])
the particular flag 0x80 is not documented as far as I can tell.
I thought I'd dig in further.
Firstly, note that re appears to cache patterns as if you repeat the same re.compile, it returns the same object and doesn't spit out the parse tree. There is a re.purge function for purging this cache but while this is mentioned in help(re) it is not in the main documentation.
Secondly, note that the flag 0x80 is actually defined as DEBUG in the re module, so a more robust form would be:
re.compile(pattern, re.DEBUG)
A source code comment for DEBUG and another undocumented flag TEMPLATE (which supposedly disables backtracking) mentions:
# sre extensions (experimental, don't rely on these)
which explains why they aren't documented.
In the Python source code, there is also a Scanner class defined with the comment "experimental stuff (see python-dev discussions for details)"
A quick search of the python-dev mailing list found nothing. Perhaps a python core development could fill us in.
by : Created on Nov. 3, 2008 : Last modified Nov. 3, 2008 : (permalink)
Cleese and a New Toolchain
Back in July 2003, I had an idea to "make the Python intepreter a micro-kernel and boot directly to the Python prompt". Thus started Cleese, which I worked on with Dave Long. We made a good deal of progress and I learned a tremendous amount.
In February 2007, I moved Cleese from SourceForge to Google Code Project Hosting in the hope of restarting work on it. In between 2003 and 2007 I'd become a switcher and so I needed to work out how to do on OS X what I'd been doing with a very strange hybrid of Windows command line and Cygwin before. Alas I never got around to that part.
Then about a week ago, inspired by Brian Rosner's interest in the project, I decided to give it another go. I also decided to use it as an opportunity to finally learn Git.
First goal: build a "hello world" kernel (no Python yet). Fortunately I had one from the initial stages of Cleese 2003, but it wouldn't build. In particular ld was barfing on the -T option used to specify a linking script (which OS X's ld doesn't support).
After asking some questions on the #osdev channel on freenode, I discovered I'd need a completely new gcc and binutils toolchain to support i386-elf. This didn't turn out to be difficult at all, though.
Here were my steps:
export PREFIX=/Users/jtauber/Projects/cleese/toolchain export TARGET=i386-elf
cd ~/Projects/cleese curl -O http://ftp.gnu.org/gnu/binutils/binutils-2.19.tar.gz mkdir toolchain tar xvzf binutils-2.19.tar.gz cd binutils-2.19 ./configure --prefix=$PREFIX --target=$TARGET --disable-nls make make install cd .. curl -O http://ftp.gnu.org/gnu/gcc/gcc-4.2.4/gcc-core-4.2.4.tar.bz2 bunzip2 gcc-core-4.2.4.tar.bz2 tar xvf gcc-core-4.2.4.tar cd gcc-4.2.4 ./configure --prefix=$PREFIX --target=$TARGET --disable-nls --enable-languages=c --without-headers make all-gcc make install-gcc
Now my "hello world" kernel builds. Next goal...working out how to programmatically build disk images for VMware Fusion (or, failing that, Qemu)
by : Created on Nov. 3, 2008 : Last modified Nov. 3, 2008 : (permalink)
Cell naming
My previous post introduced my adventures into C. elegans.
I've gone ahead and implemented my own little cell lineage browser using django-mptt. Once I've added more functionality, I'll put it online.
But for now, I'm intrigued by the naming of cells in the lineage. In particular, the majority of cells are named by appending either 'a' or 'p' to the parent cell. What do 'a' and 'p' stand for?
As an example:
P0 -> P1' -> P2' -> C
but then
- C divides into Ca, Cp
- Ca divides into Caa and Cap; Cp divides into Cpa and Cpp
Caa, Cpa then have a slightly different progression than Cap and Cpp:
- Caa and Cpa respectively split into Caaa, Caap and Cpaa and Cpap
- these then split into Caaaa, Caaap, Caapa, Caapp, Cpaaa, Cpaap, Cpapa and Cpapp
- these then split into the 16 you'd expect except that Cpapp splits into what are called Cpappd and hyp11, Caapp splits into Caappd and PVR and Caapa splits into Caapap and DVC.
Cap and Cpp progress as follows:
- they split into Capa, Capp, Cppa, Cppp as you'd expect
- these split into Capaa, Capap, Cappa, Cappp, Cppaa, Cppap, Cpppa, Cpppp as you'd expect
- these then split into Capaaa, Capaap, Capapa, Capapp, Cappaa, Cappap, Capppa, Capppp, Cppaaa, Cppaap, Cppapa, Cppapp, Cpppaa, Cpppap, Cppppa, Cppppp
- and finally the 32 you would expect except Cppppp splits into what are called Cpppppd and Cpppppv
This is just the C lineage which is less than 10%. But I'd love to know what the 'a' and 'p' stand for; what the 'd' and 'v' stand for; and why hyp11, PVR and DVR get such a distinct names.
UPDATE: I added a "cell type" field to my browser and it revealed a couple of useful things: the "leaf nodes" (i.e. final cells) from Cap and Cpp are all marked as of cell type "muscle". The leaf nodes from Cpa (including hyp11) are all marked cell type "hypodermis". The leaf nodes from Caa are a little more interesting: The Caaa... leaf nodes are all "hypodermis". The leaf nodes from Caap are the most interesting, though. Caappd is "hypodermis", Caapap is marked as dying, and PVR and DVC are neurons.
UPDATE 2: Just as a point of comparison, there is another founder cell D whose descendants are a lot cleaner. D results in 20 cells, all of type "muscle". All are named with a/p. The only reason it's not a power of 2 is the two D{a|p}pp split into 4 whereas the others at that level split into only 2.
UPDATE 3: Based on http://en.wikipedia.org/wiki/Anatomical_terms_of_location I'm now convinced a, p, d, and v refer to anterior, posterior, dorsal and ventral respectively.
by : Created on Nov. 2, 2008 : Last modified Nov. 2, 2008 : (permalink)
C. elegans
I don't normally talk about biology because I don't know much about it. Growing up, I was the physicist and my sisters were the biologists. But I'm interested in the computational modeling of just about anything so I've long been interested in biological simulations, artificial life, etc and have recently been getting in to computational neuroscience in a fairly big way.
I can't remember when I first read about Caenorhabditis elegans (henceforth abbreviated, as it is by biologists, to C. elegans) but it was probably about a year ago and it totally blew my mind.
C. elegans is a tiny roundworm, about one millimeter long but what is remarkable is just how much we know about it. How much? well, we know every single cell and how it develops from the single cell zygote. We know every single neuron and how the entire brain is wired. That's pretty incredible. Oh, and of course we've sequenced the entire genome.
C. elegans, along with fruit flies and zebrafish, is an example of a model organism. Model organisms are those that have been studied in great depth in the hope of understanding organisms in general (including humans). Numerous characteristics make a particular organism suitable as a model. In the case of C. elegans I think it's how quickly they generate and the fact they have a very defined development and fixed number of cells. They can also be revived after being frozen.
Now C. elegans are almost always hermaphrodite, although a tiny fraction are male. The hermaphrodites have 959 cells and, as I mentioned, we know how each of them developed from the initial zygote. So P0 splits in to AB and P1', P1' into EMS and P2', EMS in to E and EMS, E into Ea and Ep, and so on. This tree structure is called the cell lineage or pedigree and it's available online at http://www.wormbase.org/db/searches/pedigree. For each cell, there's also an information page and that information is also available in an XML format (e.g. http://www.wormbase.org/db/cell/cell.cgi?name=EMS;class=Cell. Because I wanted to dig around a little more, I ended up writing a data scraping script in Python to download all the XML files (parsing each one to find out what the daughter cells were then recursing).
The data I've downloaded also includes the neuronal wiring. At some point I'd like to do a little Django app for navigating around the data in a way that's a little friendlier for the layperson. Might also be a good excuse for me to try out django-mptt.
The data is all in a format that is shared across different model organism research projects and there is open source software for dealing with this data (especially the genomic data). For example, GBrowse is used for browsing and searching the genome of both C. elegans and the fruit fly. GBrowse is part of the GMOD project. Most of the stuff looks like it's Perl CGI scripts.
In my fascination with computer modeling but my complete ignorance of the state of biology, I wonder how far we are from cell-level simulations of organisms like C. elegans. Do we know enough to even begin to think about doing this for a 959-cell organism? I mean, isn't the Blue Brain project supposed to eventually simulate a 10,000-cell neocortical column? (edit: it already is, see comments below) Or how far are we from simulating the cell develop of C. elegans? i.e. given P0 (including the genome), press play and get the 959 cells of the C. elegans adult hermaphrodite at the end. The fact that (edit: one of) the most powerful computer(s) in the world and a multi-year project are what it's going to take for 10,000 cells, I guess we're not going to be writing C. elegans simulators in Python on our desktops any time soon.
But hey, it would sure be cool.
by : Created on Nov. 2, 2008 : Last modified Nov. 2, 2008 : (permalink)
How I View Blogging
(I'm trying to blog every day—however, if I want to say something in the afternoon and I've already blogged that day, I probably won't postpone posting just to stretch things out. That will likely mean more than 30 posts this month although will reduce the chance of me having something to say every day)
In his first post for the month, Brian Rosner talks about his preference for the "article" type of blog entry than the "random opinion and links" type of entry. It's not clear if that's a preference for the entries he wants to write or the entries he wants to read. He also asks his readers what their take is.
As I've thought (and written) about the topic before, I thought I'd post my random opinions here rather than just in comments on Brian's blog (or though afterwards, I may go link there).
Comments vs Trackbacks
Which segues nicely into the first point: I like giving more detailed responses to a blog post in another blog post rather than just a comment. In fact, the reason I didn't add comments when I first implemented this blog software was I wanted people to reply on their own blogs. Back in 2004 that seems more the "blog way". In a post from that time Blogs, Annotations, Comments and Trackbacks I talked about trackbacks (notifying resource A that resource B talks about it) as the fundamental idea—it's just Web annotation really, but trackbacks are primarily blog to blog and comments are really just a variant where there annotating resource is actually inlined with the annotated resource (and generally persisted on the same system, although not always).
Don Park had an idea called Conversation Categories where you could host your responses but still mark them as part of a particular conversation. I never really saw this done beyond broad tagging.
Paucity of Inbound Links
One thing that's always been unusual about my own blog is the paucity of inbound links relative to number of readers. When I've compared my stats with others who've published them, I have a high subscriber count but low number of incoming links.
I've never really worked out what that would be. I guess people find my posts interesting but not noteworthy.
Blogs as Conversations
Back in Belated Thoughts on Blogs and Wikis, I talked mostly about the nature of wikis but also made the comment that while wikis are about collaboration, blogs are about conversations.
I wonder if that's as true any more. Has the conversation moved to twitter? See more below.
Blog to Contribute to Your Tribe
I've long be inspired by Tom Peters' view that loyalty is no longer to companies but to professions and networks. Nowadays I think that's better rephrased as loyalty to 'tribes'. A few years ago I gave a talk to a business group where I basically said contributing to your tribe was the best way to "network" and, in particular contributing by sharing knowledge.
Back in the late 90s people were more likely to know me because of posts to mailing lists like xml-dev. Nowadays someone at a conference is far more likely to come up to me and say "oh hi James, I read your blog".
Blogging is a great way to contribute to your tribe(s).
Planetary Effects
I'm on both Planet Pythons. The fact I don't have category-specific feeds means all my non-Python stuff goes to the Python planets too. No one has ever complained to me about it (and, in fact, some people have thanked me for my topic diversity) but I still sometimes feel awkward about it.
One thing's for sure, nothing gets comments like a Python-related post with code included.
The Twitter Effect
There is no doubt that Twitter reduced the amount of blogging I do. Reflecting on this, it could be that blogging was partly fulfilling a desire to tell the world what I was up to and Twitter now does that. I think it's more than that, though. I think it's that Twitter has also taken much of the conversation.
I was always hesitant to post naked links to my blog but now Twitter has completely taken away the possibility of me doing that.
Also, if I have a question that can be expressed in 140 characters, I'll ask it on Twitter whereas I may have previously blogged a longer version of the question.
Twitter also has an impact on the reading side. I can now find out what a friend is up to via Twitter or their Facebook status rather than them having to do a blog post.
Why I Blog
In Blog Goals of Lack Thereof I talked about the fact that blogging is for scribbling or making announcements about projects, not, for me, a project in itself.
Back in Thank You Blog Readers I said:
I think I'll still just continue to blog about things that interest me and things that I'm working on. After all, pretty much every single topic I've written on has put me in contact with some interesting person that I've learnt and am continuing to learn new things from.
How I View Blogging As Reader
I read to be informed and, occasionally entertained. I want to learn stuff. I want to trigger new ideas. I want to be informed what's going on in particular communities. I want to to be informed what's going on with particular friends or their projects. I read too many feeds to deal with too many long articles.
How I View Blogging As a Writer
I want to inform. I want get a better understanding of things by being forced to articulate them myself. I want to be corrected when I've done something stupidly and want have my solutions improved upon. I want to find other people who are working (or wanting to work) on similar projects to me. I want to keep people up-to-date with what I'm working on.
In Conclusion
I think I'll continue to blog. They won't be long articles. They won't be naked links. There'll be some announcements, but it will mostly be snippets of thought as I learn and try to interact with other learners.
by : Created on Nov. 1, 2008 : Last modified Nov. 1, 2008 : (permalink)
Two Fun(ctional) Questions
Consider the following series of functions:
def x(a): if callable(a): return lambda i: a(i) else: return a
then
def x(a): def xx(b): if callable(b): return lambda i: a(b(i)) else: return a(b) return xx
then
def x(a): def xx(b): if callable(b): def xxx(c): if callable(c): return lambda i: a(b(c(i))) else: return a(b(c)) return xxx else: return a(b) return xx
and so on...
Two questions:
- how would you write a single recursive or iterative version of this that could handle cases of any depth?
- what would you call what this function x is doing?
by : Created on Nov. 1, 2008 : Last modified Nov. 1, 2008 : (permalink)
Blogging Every Day in November
For perhaps the third time, I'm going to try to blog every day for a month, starting tomorrow. I thought I'd make this meta post today as making it my post for tomorrow seems like it would be cheating.
See you back here regularly!
by : Created on Oct. 31, 2008 : Last modified Oct. 31, 2008 : (permalink)
Pinax 0.5.0 Released
Well, I don't need to go into the history as you've all seen the video, but five months ago a project that had been brewing in my mind for a while started taking form and now I'm thrilled to announce the first official release of Pinax.
Thanks to Brian Rosner, Greg Newman, Jannis Leidel and Eric Florenzano—the core team—as well as the authors of additional third party apps we used and people who provided translations, bug reports, etc.
There'll hopefully be a number of big Pinax news items here over the next couple of months, but for now, you can join in the fun and download 0.5.0 from the Pinax Download Page.
by : Created on Oct. 28, 2008 : Last modified Oct. 28, 2008 : (permalink)
Guinea Pigs, Karaoke Machines and Minimum Sample Size
Yesterday I read a very strange quote:
2.86% of guinea pigs admitted to veterinary hospitals in the survey had been injured by karaoke machines
from Charlie Stross talking about an article in The Register.
It got me wondering what the minimum sample size would be to get 2.86%. It turns out, to the right number of significant digits, 1 in 35 gives 2.86% so it's possible it was only 1 case out of only 35 in the survey.
Here's some Python code for working out the minimum sample size that will result in a given decimal. Note that decimal is to be given as a string so significant trailing zeroes can be used. e.g. min_sample("0.1") == 7 whereas min_sample("0.10") == 10 as you would expect.
def min_sample(decimal): fl = float(decimal) assert 0 < fl < 1 sig_digits = len(decimal) - 2 for sample_size in range(1, (10 ** sig_digits) + 1): if round(round(fl * sample_size) / sample_size, sig_digits) == fl: return sample_size
So the next time you read 22% of X or 24% or Y or 2.86% of Z you can quickly work out the sample size could be as low as 9, 17 or 35 respectively.
P.S. I leave it as an exercise to the reader to rewrite using the decimal module and decide whether it's worth it.
by : Created on Oct. 18, 2008 : Last modified Oct. 18, 2008 : (permalink)
HSL Gradients
A few months ago, I wrote a post about Creating Gradients Programmatically in Python. The main use was to generate gradients for things like web site nav bars:

You might try to achieve the glassy look of the default nav button in the first example with a simple linear gradient from #516c7a to #7291a1 and then from #5f7f8f to #87a2af. The problem with dealing with RGB is that it's very difficult to know how to do a variation that differs in hue but has the same saturation and lightness. Or how to have more saturation but keep the hue constant.
So using the formulae from the Wikipedia page on HSL and HSV I implemented a version of gradient.py that takes HSL values instead of RGB.
Instead of specifying #516c7a to #7291a1 and #5f7f8f to #87a2af, this:
is achieved by specifying HSL (200°, 0.2, 0.40) to (200°, 0.2, 0.54) then (200°, 0.2, 0.47) to (200°, 0.2, 0.61). Note that this is much cleaner as the hue stays constant as does the saturation. Only the lightness varies to give the shiny look.
Just by increasing the saturation to 0.5 and keeping everything else the same, we get:
We can then change the hue from 200° to 0°:
With a little bit of experimentation, I found the button looked nicer if it had a slight glow, achieved by increasing the saturation by about 50% at the top and bottom. Here are the same three buttons with saturation 0.3 → 0.2 → 03 (instead of constant 0.2) and 0.7 → 0.5 → 0.7 (instead of constant 0.5):
In every case the lightness gradient was the same from one button to the next.
I found, though, that to get the shiny black, the original lightness didn't work:
Not even varying the lightness by a constant really worked, so the following is achieved with (0, 0.0, 0.40 - 0.25) to (0, 0.0, 0.54 - 0.20) and then from (0, 0.0, 0.47 - 0.25) (0, 0.0, 0.61 - 0.25):
Here is my HSL2RGB function and the reverse RGB2HSL:
[a commenter below has pointed out Python includes functions for this in the standard library already — oh well]
def RGB2HSL(R, G, B):
fR = float(R / 255.0)
fG = float(G / 255.0)
fB = float(B / 255.0)
ma = max(fR, fG, fB)
mi = min(fR, fG, fB)
if ma == mi:
H = 0
elif ma == fR:
H = (60 * ((fG - fB)/(ma - mi))) % 360
elif ma == fG:
H = 120 + 60 * ((fB - fR)/(ma - mi))
elif ma == fB:
H = 240 + 60 * ((fR - fG)/(ma - mi))
L = (ma + mi) / 2
if ma == mi:
S = 0
elif L <= 0.5:
S = (ma - mi) / (2 * L)
elif L > 0.5:
S = (ma - mi) / (2 - 2 * L)
return H, S, L
def HSL2RGB(H, S, L):
if L < 0.5:
q = L * (1 + S)
elif L >= 0.5:
q = L + S - (L * S)
p = 2 * L - q
hk = H / 360.0
tR = hk + 0.333333
tG = hk
tB = hk - 0.333333
def color(t):
if t < 0:
t += 1
if t > 1:
t -= 1
if t < 0.166666:
c = p + ((q - p) * 6 * t)
elif 0.166666 <= t < 0.5:
c = q
elif 0.5 <= t < 0.666667:
c = p + ((q - p) * 6 * (0.666667 - t))
else:
c = p
return c
R = int(color(tR) * 255)
G = int(color(tG) * 255)
B = int(color(tB) * 255)
return R, G, B
by : Created on Oct. 18, 2008 : Last modified Oct. 18, 2008 : (permalink)
London Python Meetup and FOWA
I'm in London this week and next for personal reasons but I'm taking the opportunity to attend FOWA tomorrow and Friday.
I'm also delighted to have a last minute gig talking about Pinax at the London Python Meetup tonight.
If you're going to be at the Python Meetup and/or FOWA, I look forward to catching up with you!
by : Created on Oct. 8, 2008 : Last modified Oct. 8, 2008 : (permalink)
Photo Meme
I'm late to this meme because I haven't been on my laptop (with camera) for ages. But now that I'm traveling, here I am:

This is at Logan airport on my way to London.
by : Created on Oct. 5, 2008 : Last modified Oct. 5, 2008 : (permalink)
Programming Languages I've Learned In Order
- BASIC (TRS-80 Model I)
- BASIC (TRS-80 Color Computer)
- 6809 Assembly
- AppleSoft BASIC
- 6502 Assembly
- BASIC (BBC Micro)
- Prolog
- Pascal
- Turbo Pascal (with OO extensions)
- C++
- C (yes, I did C++ before straight C)
- LISP
- Perl 4 (dabbled in 5)
- QBasic
- Scheme
- Java
- VisualBasic
- Python
- x86 Assembly
- Javascript
Those in bold are the ones I've worked with recently.
(note I haven't included XSLT or TeX although they are Turing complete. Nor things like dBase II and SQL)
(idea via Dougal Matthews)
UPDATE: I'm not quite sure what to make of this, but I forgot javascript the first time around :-)
UPDATE: Added a couple more BASIC dialects and made current languages bold. You're wondering what I'm using Pascal for, right?
by : Created on Sept. 28, 2008 : Last modified Sept. 29, 2008 : (permalink)
A Man's Gotta Do
For those of you who've been asking for A Man's Gotta Do (What A Man's Gotta Do) from Dr Horrible:
Previous songs available at More Dr Horrible.
by : Created on Sept. 27, 2008 : Last modified Sept. 27, 2008 : (permalink)
Why 13th Chords
As the background to my music theory is more classical in nature, it used to puzzle me when I saw jazz chords like C9, B♭11 or F13. I mean, I knew what a 9th, 11th and 13th note were but I wondered why you'd call a note a 9th rather than a 2nd, or a 13th rather than a 6th and so on.
After all, when you talk about chord, you're normally talking about notes independent of octave. If you describe something as a C7 chord, you're not saying anything about whether the E and B♭ are in the same octave or not.
I can't remember when, but the breakthrough came when I realised that a 9th chord isn't just a major triad with the 2nd added, but one with the 2nd and 7th added, an 11th chord is one with the 4th and 7th added.
(just as an aside: the fact 2+7=9 and 4+7=11 here is an unrelated coincidence. An 11th is 4th+octave but due to the 1-based indexing used, you add 7 not 8)
Now yes, I've seen the theory books where they show a C9 as C+E+G+B♭+D and a C11 as C+E+G+B♭+D+F and a C13 as C+E+G+B♭+D+F+A but that really didn't help emphasize that it's the existence of the 7th that makes the the chord sound like (and be described as) a C9, C11 or C13 respectively instead of, say a Cadd2, Cadd4 or C6.
The 3rd and 7th are really the defining notes of a chord in Jazz, particularly comping on piano where you expect the bass to provide the root. So the final light went off when I saw the closing Jazz riff of Ben Folds Five's Underground notated. There were a bunch of triads that were marked as 13th chords. So, for example, the voicing E♭+A+D was marked as F13.
Note that that voicing has just the 3rd, 7th and 13th. The 13th is also a 6th but by calling the chord F13, it's making it clear the 7th is there as well which gives the chord a very different direction it wants to go. The 7th makes the whole chord want to resolve to a B♭, which gives the 13th/6th (the D) more of a suspended feel it doesn't have in an F6 chord.
I find not only the 13th chord a great substitute for a 7th now, especially when it's the dominant resolving to the tonic, but I also love the 7th+3rd+13th/6th way of voicing it too.
I know this is Jazz 101 but it was a breakthrough moment for me, anyway :-)
UPDATE (2012-01-01): interesting discussion on this post now on Hacker News
by : Created on Sept. 23, 2008 : Last modified Jan. 1, 2012 : (permalink)
My Talk on Pinax at DjangoCon
Including the famous Cloud27 live launch and what James Bennett described as the worst pun ever.
by : Created on Sept. 16, 2008 : Last modified Sept. 16, 2008 : (permalink)
DjangoCon, Pinax and Cloud27
This weekend just gone was DjangoCon, quite possibly the best conference I've been to (and I've been to a lot). It is certainly the only one where I've attended a talk in every single session.
Congratulations to Rob Lofthouse for a tremendous job organizing it. And kudos too to Leslie Hawthorn and the rest of the Google team for being such excellent hosts. The A/V and the WiFi were (perhaps expectedly) the best I've ever seen at a conference.
It was wonderful hanging out with so many people from the Django community, both people I'd met before at PyCon and others I knew from email, blogs, IRC or twitter. It was particularly fun to meet Russ Keith-Magee after what must be 10-15 years (Russ went to highschool with my sister)
I presented a talk on the history and vision behind Pinax which ended with the (hopefully) surprise launch of Cloud27. The talk seemed well received and people seemed to especially like the live launch :-)
My favourite twitter response to my talk was: "Pinax is every idea I've ever had." Everyone but James Bennett laughed at my Dr Horrible reference. After giving the old line "When all you have is a hammer, all you see is nails", I added "the hammer is my Pinax". (Worse pun ever, Mr Bennett claims)
Clint Ecker wrote a wonderful article about my talk at Ars Technica Ars at DjangoCon: Build your own social network with Pinax although it's a bad photo of me :-)
Judging from the response and the people that talked to be afterwards, I'm very excited about Pinax in the future.
Huge thanks to the Pinax team and especially Greg Newman for putting work in to get Cloud27 ready for launch at the conference.
by : Created on Sept. 8, 2008 : Last modified Sept. 8, 2008 : (permalink)
Back to Blogging
Longest blogging drought ever I think :-)
Was back in Australia, then back for just a few days in Boston before heading to Mountain View for DjangoCon. More in the next post on that...
by : Created on Sept. 8, 2008 : Last modified Sept. 8, 2008 : (permalink)
n.b., etc.
Last week one of my colleagues asked me if I knew what "n.b." meant. "Of course, " I said. "It's short for nota bene, Latin for note well."
It had been used in a document from someone in the UK. Apparently n.b. isn't very common in the US. I asked my colleague if he knew what i.e. and e.g. meant. Of course he did.
So then I decided to do an experiment. I wrote up the following on my whiteboard:
- e.g.
- i.e.
- n.b.
- cf.
- q.v.
- viz.
They were six Latinate abbreviations I could think of off the top of my head, roughly in order of how likely I thought it was that my colleagues would (1) have ever seen them; (2) know the meaning of them; (3) use them themselves. (Yes, there are others like etc. and ibid. but the above were the six I thought of at the time)
Anyway, it turns out the people I asked in the office were familiar with and used i.e. and e.g. but none were familiar with n.b., cf., q.v. or viz.
Feel free to comment below on which of the six you (1) have seen; (2) know the meaning of; (3) would use.
UPDATE: Professor Conrad pointed out that c.f. should be cf. which I've corrected above.
by : Created on Aug. 10, 2008 : Last modified Aug. 11, 2008 : (permalink)
Dr Horrible Ringtones
Thanks to James Bennett, I learnt how to make ringtones out of my MP3s.
So here is the Dr Horrible Main Title and the Bad Horse Phone Call as .m4r files which you load in to iTunes and sync with your iPhone.
(you may need to right click to download them)
Other songs I've done are available as MP3s from my post
More Dr Horrible
but they are too long to make into ringtones (they won't sync with the iPhone) so I have to pick which 30 second extract in each case to use. That page also has versions without vocal lines for use in Dr Horrible karaoke!
Enjoy! And go buy Dr Horrible from iTunes while you're at it :-)
UPDATE: Made the link to my existing MP3s clearer as at least one commenter missed it.
by : Created on Aug. 6, 2008 : Last modified Aug. 7, 2008 : (permalink)
More Dr Horrible
I got another request for a Dr Horrible song so here is Laundry Day / Freeze Ray from Act I:
- Freeze Ray 0.1 with vocal line on synth
- Freeze Ray 0.1 Backing without vocal line
For easy access, here are my previous three efforts:
- So They Say 0.1 (from Act III with vocal lines)
- Main Title 0.1
- On The Rise 0.1 (from Act II with vocal lines)
Enjoy! (and go buy Dr Horrible on iTunes to hear the real thing)
PS If you're Jed Whedon, I'd love to talk to you more about your scoring.
UPDATE (2008-08-04): Here are backing versions (i.e. without vocal lines) of the other two songs above:
- So They Say 0.1 Backing without vocal lines
- On The Rise 0.1 Backing without vocal lines
UPDATE (2008-08-05): Here's the Bad Horse phone call from Act II:
- Bad Horse Phone Call 0.1 without vocal lines
UPDATE (2008-08-06): Here's Brand New Day from Act II both with and without vocal lines
- Brand New Day 0.1
- Brand New Day 0.1 Backing without vocal line
UPDATE (2008-08-06): RINGTONES! Now see Dr Horrible Ringtones
UPDATE (2008-09-27): A Man's Gotta Do
by : Created on Aug. 2, 2008 : Last modified Sept. 27, 2008 : (permalink)
Pinax Project and Cloud27
The initial growth of Pinax was helped by us building a demo social networking site, but it often led to confusion about Pinax the platform as opposed to Pinax the social networking site.
The demo social networking site was (and still is) at http://pinax.hotcluboffrance.com/ but that URL also confused people not familiar with the original django-hotclub mailing list I started to discuss how to better build reusable Django apps.
Furthermore, it was becoming clear that the demo social networking site was actually useful, not just as a demo of Pinax, but in its own right.
And so, a few weeks ago, I decided that the demo site should migrate to a new, standalone site and that Pinax, the platform, needed a home.
The former will soon be launched as Cloud27 which, at the moment, is just a splash screen, but which will eventually replace http://pinax.hotcluboffrance.com/. Users of Cloud27 need not necessarily care that Pinax is underlying the site.
That leaves a site about the Pinax platform to point people to. I just launched that this morning and it's available at:
http://pinaxproject.com/
This new domain is what anyone talking about Pinax should link to — it's the new home of Pinax itself.
by : Created on July 30, 2008 : Last modified July 30, 2008 : (permalink)
Dr Horrible
Last week I kept seeing people twittering about a new episode of Dr Horrible. I had no idea what they were talking about and assumed it was some show on TV.
Then last Saturday I was on iTunes and saw mention of Dr Horrible's Sing-Along Blog featuring a picture of Neil Patrick Harris. I'm a huge NPH fanboy, so had to check it out.
It was then that I discovered it was a made-for-Web show from Joss Whedon consisting of three 13 minute episodes. Joss Whedon + NPH — it had to be good. So I bought the trio of episodes and watched them right away.
It's a huge amount of fun — the songs are catchy, the writing awesome, NPH and Nathan Fillion are both brilliant as, respectively, the wannabe evil mastermind and self-centered super hero. And Felicia Day is downright adorable as the ingenue.
This isn't your ordinary made-for-Web series. The production values are very high -- judging from the crew credits, this was shot like hour-long TV show.
After watching it a couple of times, I spent a few hours last Sunday doing a cover of the first song from Act III, the hilarious "So They Say". I've put up an instrumental (with vocal lines on synth) mp3: http://jtauber.com/2008/07/so_they_say_0_1.mp3
I'll probably do a bunch of the other songs too.
UPDATE: Main title version 0.1: http://jtauber.com/2008/07/main_title_0_1.mp3
UPDATE 2: By request, here's On the Rise version 0.1: http://jtauber.com/2008/07/on_the_rise_0_1.mp3 Enjoy!
UPDATE 3: Now see More Dr Horrible and Dr Horrible Ringtones
by : Created on July 25, 2008 : Last modified Aug. 6, 2008 : (permalink)
iPhone Stopwatch Comparison
Below is a photo of my original iPhone next to my new iPhone 3G.
The original iPhone (on the left) is still running 1.1.4 (4A102) whereas the iPhone 3G (on the right) is running 2.0 (5A345) which it shipped with.

The first thing you might notice is that 2.0 has fixed the problem with the stopwatch taking up too much space when it goes over 1,000 hours (although not the lap time)
You might also notice the colour temperature difference (the original is more blue, the 3G more yellow) that has been much talked about.
But other than that, they look pretty similar. Except that's where it surprised me. The stopwatch is almost the same on both: about 2,200 hours. But that's three months and the 3G only came out a week ago.
That's right: when iTunes synced the data between my phones, it kept the stop watch going!
As far as I can tell, the 1.4 second difference is actually due to the clock in the iPhone itself not the stopwatch specifically. If the old iPhone could still sync its time from the cellular network, the two might show identical times on the stopwatch.
by : Created on July 18, 2008 : Last modified July 19, 2008 : (permalink)
iPhone 3G First Impressions
I stood in line on Friday to upgrade to an iPhone 3G. It took about 2.5 hrs to get to the front of the line but the process after that was very easy because I was already an AT&T customer.
By the time I'd left the store, my old iPhone no longer worked as a phone.
The iPhone 3G felt funny at first but I've gotten used to it now. I think actually prefer the feel of it in my hand but it did take a day or two to get to that point. The screen also felt rougher initially but that might have just been some temporary coating and it now feels just as smooth as my old iPhone.
I immediately downloaded Monkey Ball. The accelerometer-based controls are harder to get used to than they looked in the demos. I've also bought the Things app and look forward to when it supports synchronization with the desktop version.
The App Store experience itself was pretty impressive. It is pretty amazing sitting at the airport, deciding you want a new app and buying, downloading, installing and using it right there and then.
The GPS worked nicely in conjunction with Google Maps when my girlfriend and I were going to pick up a pizza last night.
I haven't really done much data stuff over 3G yet as I'm on wireless when at home so can't really comment on how much faster it is. Certainly the signal I get in my apartment isn't any better which is unfortunate.
I haven't played around with the Mobile Me integration yet.
I'll be configuring Exchange support tomorrow at work, so I'll report how that goes.
Overall: the original iPhone was so impressive, getting the new phone was somewhat anti-climactic in comparison. If you don't have an iPhone, the 3G version will be at least as impressive as the original was a year ago. If you do have an iPhone already, the value obviously depends on how important 3G and GPS are to you.
by : Created on July 13, 2008 : Last modified July 13, 2008 : (permalink)
iPhone Upgrade
So, I'm planning on upgrading my iPhone, if not Friday then pretty soon afterwards. I may upgrade my existing phone to the 2.0 software right away, though, just for a sneak preview (assuming the software update is available on Friday too).
I'm not clear what happens to my existing contract. I hope I can just roll it over to the new plan (and obviously stop using my existing iPhone, except as an iPod Touch with a camera). Surely they won't make me have two contracts in parallel if I only plan to use one phone (and transfer my number across).
I'm definitely looking forward to the faster data speeds. I'm also hoping it works better in my apartment. Location doesn't seem to be the problem (it works fine outside) but rather the building construction prevents me getting a signal inside. No idea if 3G will make a difference there or not.
by : Created on July 8, 2008 : Last modified July 8, 2008 : (permalink)
Turing Chess
At the HTM Workshop there was a lightning talk by David Doshay on Computer Go which is another application I thought of as soon as I read On Intelligence.
During the break after his talk a bunch of us were talking and he basically said that a lot of researchers were moving to Go because Chess was a solved problem (perhaps I should have pursued Go research more back when I was interested in 2001).
I asked if he knew of anyone who, instead of switching from Chess, was going back to make Computer Chess more human-like rather than simply better. He wasn't aware of any such work.
It seems to me that an interesting pursuit would be a sort of Turing Test of Chess where the goal is not to beat the human but to trick other humans reading a transcript of the game as to which was the human player.
(Yes, I read Blondie24: Playing at the Edge of AI a few years back)
by : Created on July 7, 2008 : Last modified July 7, 2008 : (permalink)
The Rocker
My friend and filmmaking partner, Tom Bennett used to manage a band and still owns a Silver Eagle Coach from back in the day. About a year ago, he was contacted by 20th Century Fox interested in using the coach in a film.
The film was The Rocker (official site, IMDb) which comes out this month. It's the story of a failed drummer (played by The Office's Rainn Wilson) who, after 20 years of seeing the band he got kicked out of rise to stellar heights, finally gets a second chance.
Tom invited me to an advanced screening last week (it was fun going into the cinema and saying "we're on the list" :-)
The movie was a lot of fun. A predictable plot but well handled. Wilson's character seemed to me to have just the right balance of flaws and virtues. Solid acting all round, although the highlight comedically was Jason Sudeikis as the band manager. He got the best lines and delivered them with impeccable timing.
The original songs were excellent as well.
Pete Best (appropriately) has a cameo but I missed it.
Tom and his son Travis (who travelled up to Cleveland for a few days of shooting) also had roles as background and I spotted them (not that Tom would have let me miss that :-)
by : Created on July 6, 2008 : Last modified July 7, 2008 : (permalink)
On Intelligence and the HTM Workshop
Like a lot of geeks, I've been interested in how the brain works for most of my life. Artificial Intelligence was always one of my interests within computing (and part of what got me interested in linguistics at a very early age).
Within my linguistics research, I've always been interested in models that are biologically plausible so it was a huge delight to read Jeff Hawkins' On Intelligence back in early 2005 and find a theory that was biologically-based and believable from a linguistics point of view. One prominent psycholinguist told me in 2006 that it was one of the most promising theories he'd ever read.
After reading the book, I promptly went out and built a library (as I am wont to do) of about 20 books on general neuroscience, computational neuroscience and the relationship between the brain and language. I started thinking about how to implement the ideas and, after reading some of Jeff's and Dileep George's early papers, augmented the library further with books on Bayesian networks, belief propagation, etc.
When Jeff and Dileep started Numenta and eventually released an early version of their Hierarchical Temporal Memory (HTM) platform in Python, I was particularly excited to try it out, in particular applying it to linguistics. I started the htm-ling mailing list to gather other people interested in applying HTM to models of language. It turned out to be hard to get word out to other people interested in HTM and linguistics, however.
I never got very far with Numenta's code, mostly because there were just too many other things I was working on.
But then a couple of months ago, I found out Numenta was running a workshop / conference. I thought it would be an excellent opportunity for me to (a) get back up to speed with what Numenta was doing and how to use their NuPIC platform; (b) meet other people interested in applying HTM to linguistics.
So a couple of weeks ago, I attended the first Numenta HTM Workshop. I had a great time. It was great to meet Jeff and the rest of the team. Dileep's talk on the algorithms in NuPIC was particularly helpful to me in understanding how things work.
There were a number of people who expressed an interest in the application to linguistics so in the evening I ran a BOF. None of the attendees (as far as I could tell) were linguists by training so I didn't really get to talk too technically from a linguistics perspective. The boost to the mailing list membership hasn't created any more discussion yet either.
But I am still hopeful that an HTM-like approach (whether in the form of NuPIC or some other implementation) might be useful in building biologically-plausible models of language processing.
by : Created on July 5, 2008 : Last modified July 6, 2008 : (permalink)
Changes to Google Maps Satellite Images
It used to be obvious in Google Maps where the boundaries of different satellite images were. Each image had different brightness, contrast, colour, etc which gave away the stitching.
I always wondered whether there were techniques to normalize that.
I guess there are: Today I noticed the satellite images are stitched together seamlessly.
I also noticed some level-of-detail differences between land and ocean and that is also done pretty seamlessly.
It actually makes navigating around the satellite view a little eerie.
Anyone know when the change was made?
UPDATE: Actually it depends on the zoom level. Compare this to this. And notice the image credits are different. Interestingly, my home town of Perth looks fully normalized at all scales, even though the image sources are still TerraMetrics for the large scale and DigitalGlobe/GeoEye for the small scale.
by : Created on July 4, 2008 : Last modified July 4, 2008 : (permalink)
The Annotated Turing
Some books entertain, some inform; some confirm what you already knew, some make you change your mind about something. But then there are some books that just make you think "wow! I wish I'd written that".
For me, Charles Petzold's The Annotated Turing falls into that last category. It's a book worth reading not only for the topic itself but the way it's presented.
He provides the necessary background before working through Turing's famous 1936 paper "On computable numbers, with an application to the Entscheidungsproblem" with rich annotations at every stage, including biographical details.
If you are interested in the foundations of mathematics, computability, Turing's work, or even just ways of explaining mathematics in a historical context, I highly recommend this book.
by : Created on July 3, 2008 : Last modified July 3, 2008 : (permalink)
Pinax Progress III
In the six weeks that it's been around (that's not six weeks since launch, that's six weeks since coding started), the Pinax platform and community has grown in ways I never expected.
Since I last blogged about it, we've added:
- localization into Brazilian Portuguese and Hebrew
- timezone localization
- external blog aggregation
- wikis
- threaded discussions
- bookmarks with voting
- contact import
- blogs with tagging and threaded comments
It is becoming clear that what was originally intended to be a demo site is a useful site in its own right, irrespective of whether you care or even know about the Pinax platform underlying it. So it will be moving over to a new site with a new identity soon.
by : Created on July 2, 2008 : Last modified July 2, 2008 : (permalink)
Back to Blogging
Last month was my worst blogging drought ever.
It happened for a number of reasons: I was travelling almost 3 weeks out of the month; free time was spent on other projects; Twitter replaced a lot of my drive to blog (and subsequently, the django-hotclub IRC channel replaced a lot of my drive to Twitter).
I'm going to try to blog a lot more regularly this month. I have a long list of things to blog about.
by : Created on July 1, 2008 : Last modified July 2, 2008 : (permalink)
Two Podcast Interviews
In the last week two podcasts have come out which I appear on.
The first is the Google Summer of Code podcast where Titus Brown and I were interviewed about the Python Software Foundation's participation in both GSoC and GHOP.
http://google-opensource.blogspot.com/2008/05/podcast-with-pythonistas.html
The second is This Week in Django where I talk a little about myself and (more importantly) Pinax and the Hot Club of France.
http://blog.michaeltrier.com/2008/6/2/this-week-in-django-24-2008-06-01
I sound much better in the second one because I recorded my track locally with a large diaphragm condenser mic and sent the audio file for mixing. In the first one, it's just my laptop mic going over Skype.
They were both fun although I babble too much, especially on the TWiD podcast.
by : Created on June 4, 2008 : Last modified June 4, 2008 : (permalink)
Question-Driven Commenting
I've always loved Titus Brown's notion of stupidity driven testing. It's okay to make a mistake but you write a test to make sure you don't do it again.
With Pinax, I've been adopting the sister practice of "question-driven commenting". When someone asks me what a function does or how to implement a particular extension, that's when I go and add comments to the code.
Of course, the person asking the question could be me :-)
by : Created on May 28, 2008 : Last modified May 28, 2008 : (permalink)
Pinax Progress II
Yesterday I reported that we'd added the following to Pinax in the last 24 hours:
- user profile pages
- gravatars
- user-to-user messages (via django-messages)
- announcements (a new app, django-announcements)
- OpenID support
- invitations to join
Well, in the last 24 hours we've added to that:
- translations into German, Spanish and Swedish
- a new design / logo
- auto-completion on message recipient field
- a basic Twitter clone
- OEmbed support in tweets
- the beginnings of tribes (i.e. groups)
I could not have hoped for a more productive weekend!
Earlier in the day I did a rough count purely based on file-size and estimated that Pinax is:
- 63% re-usable apps;
- 10% local app;
- 13% templates;
- 8% localization;
- 5% media;
- 1% util
which bodes well for the original goal of Pinax: to jump-start some reusable Django apps.
by : Created on May 26, 2008 : Last modified May 26, 2008 : (permalink)
Pinax Progress
Here is what the team of brosner, leidel, floguy and myself have added to Pinax in the last 24 hours:
- user profile pages
- gravatars
- user-to-user messages (via django-messages)
- announcements (a new app, django-announcements)
- OpenID support
- invitations to join
Check it out at http://pinax.hotcluboffrance.com/
by : Created on May 25, 2008 : Last modified May 25, 2008 : (permalink)
Programming as Jazz
I'm starting to appreciate that programming has more similarities to Jazz than just the project naming conventions encouraged by Django.
When I started the Hot Club of France mailing list (named for Django Reinhardt's Quintet du Hot Club de France) I explicitly mentioned it was about writing reusable apps that "jam" well together. But I'm realising that it's as much about the developers jamming as the code itself.
Ever since the inception of the Hot Club project, I've thought about cloning Web 2.0 websites using reusable Django projects. I noticed at the time that this is sort of like the "contrafact" approach of early Jazz where you would improvise new songs using the chord progressions of existing songs. The analogy isn't perfect but I do think the term "contrafact" is a great one to use for the programming practice.
Things are really starting to come together with Pinax and the conversations I've been having recently with other Django developers keen to jam with me on it reminds me a lot of stories I've read of the bebop years. You check out someone's work, think it will work well with your own style and start doing some improv together. Awesome stuff!
Things are really starting to come together at http://pinax.hotcluboffrance.com/
Just call me yardbird :-)
by : Created on May 23, 2008 : Last modified May 23, 2008 : (permalink)
Funcom's Epic Fail
So the other night I decided to purchase the adventure game Dreamfall by FUNCOM as a digital download. They provide their own downloader, that's fine. But
- the downloader first requires you to install .NET 2.0 yourself
- the downloader prompts you to enter "the provided key" but the email receipt from FUNCOM didn't mention the word "key". It had something it called a "license number".
- I typed in the license number but the downloader came back "invalid coupon" (I'm thinking at this stage "is it a key, a number or a coupon" ?!?!)
- the receipt says to email marketing@funcom.com if there are any problems with digital downloads so I email that address
- I get back an autoresponse saying "If you have not submitted this via our web form at [link provided] then your mail may be removed by our spam filter. Please resubmit your request using this form."
- I click on said link and get a 404.
EPIC FAIL FUNCOM!
by : Created on May 22, 2008 : Last modified May 22, 2008 : (permalink)
Creating Gradients Programmatically in Python
For various sites I often want to create a narrow gradient image. This site has two, for example, the grey background gradient and the purple header gradient.
Rather than having to open up a drawing tool every time I want to create one of these, I thought I'd write a Python script to generate a PNG of a gradient according to declarative specifications.
The result is
http://jtauber.com/2008/05/gradient.py
Only linear gradients are currently supported although you can have any number of them at different vertical offsets and it's easy to modify the code to support other gradient functions.
The code itself is 50 lines long and has no dependencies other than the standard library. I've included some samples based on the gradients on jtauber.com and Pinax.
For example, this gradient:

is produced with the following code:
write_png("test2.png", 50, 90, gradient([ (0.43, (0xBF, 0x94, 0xC0), (0x4C, 0x26, 0x4C)), # top (0.85, (0x4C, 0x26, 0x4C), (0x27, 0x13, 0x27)), # bottom (1.0, (0x66, 0x66, 0x66), (0xFF, 0xFF, 0xFF)), # shadow ]))
The 30-line write_png function could also be used more generally for generating any RGB PNGs.
by : Created on May 18, 2008 : Last modified May 18, 2008 : (permalink)
Metrics Provide An Inner Product
Another post for the Poincaré Project.
We've already seen that a one-form is a linear function from a vector to a (for our purposes) real number. On a manifold, one-forms correspond to stack-type vectors being applied to arrow-type vectors by counting how many "stacks" the arrow passes through.
In the previous post Metrics As Mappings Between Arrows and Stacks, we saw that a metric is an extra bit of structure that describes how to map between arrow-type vectors and stack-type vectors.
So, in summary:
- a metric tells you how to go from an arrow-type vector to a stack-type vector
- a stack-type vector can be applied to another arrow-type vector to get a real number
These two facts can be combined to let you take two arrow-type vectors and get a real number out of them.
This has parallels with currying in functional programming.
Recall that if a function "add" takes two integers and returns an integer, it can be viewed as a function that takes one integer and returns a function that takes one integer and returns an integer.
add :: Int -> Int -> Int
Now, a one-form is a function that takes a vector and returns a real. In other words:
Vector -> Real
So it is easy to see that if you curry a real-valued function that takes two vectors you get:
Vector -> Vector -> Real
In other words, a function taking two vectors to a real is equivalent to a function from a vector to a one-form.
So if you have a metric that can convert between vectors and one-forms (or, in the context of a manifold, between arrows and stacks) then you also have a function from two vectors to a real.
Such a function is called an inner product or dot product. Often the notion of an inner product is defined first, before one-forms are introduced (if at all). In fact, some texts will define a metric to be an inner product. It is best for our purposes, though, to think of the metric's fundamental purpose as being converting between arrows and stacks (and back again) and the inner product as being an extra concept we get for free.
by : Created on May 11, 2008 : Last modified May 11, 2008 : (permalink)
Introducing Pinax
In the post Reusable Django Apps and Introducing Tabula Rasa I mentioned my project to create an out-of-the-box Django-based website with everything but the domain-specific functionality.
At the time I was calling it Tabula Rasa but now I've settled on the Greek word Pinax, proposed by Orestis Markou.
So far it's just my new django-email-confirmation app tied together with password change and reset, login/logout, with the beginnings of a tab-style UI. There's a ton more I want to refactor out of my existing websites to put into it as well as adding support for OpenID and the stuff I'm starting to do for django-friends.
Even if one doesn't use Pinax as the starting point of a website, I'm hoping it will prove very useful for another goal, namely a "host" project to develop and tryout reusable apps.
The initial code is available at http://code.google.com/p/django-hotclub/ under /trunk/projects/pinax and there is a running instance for you to try out at:
by : Created on May 10, 2008 : Last modified May 10, 2008 : (permalink)
Elite Oolite
When I lived in Brunei in the mid-80s, a neighbour had a BBC Micro and I would go over there to play the space trading game Elite. The hidden-line wireframe graphics and massive procedurally-generated universe seemed amazing to me at the time and it was definitely the kind of software I aspired to one day write myself. At the time, I taught myself trigonometry to do 3D graphics but never got to hidden line removal :-)
I was aware of various Elite clones over the years, but the other day I stumbled across Oolite, an open-source Mac OS X version with modern OpenGL graphics. Simply amazing and just as addictive as I remember the original being. It also seems to be highly pluggable, with numerous extensions available to add both to the UI and gameplay.
by : Created on May 9, 2008 : Last modified May 9, 2008 : (permalink)
LOTRO on VMware Fusion
I've hardly played Lord of the Rings Online at all the last six months and not at all the last three.
My only copy of Windows is a VMware Fusion instance and LOTRO doesn't work on VMware Fusion. That is...until now.
I was excited to hear that the new VMware Fusion 2.0 beta 1 supported pixel shaders in DirectX 9 and I wondered if that meant LOTRO would work. I downloaded the beta, which JUST WORKED with my existing VM (which wasn't even shut down). I spent an hour or so updating LOTRO but my first attempt to start the game failed.
The error message was different, though. Instead of being about the graphics adapter it was a complaint about a Game Error 127. A Google search revealed this post and so I tried making the config change they suggested there.
And BINGO! I can now run Lord of the Rings Online on VMware Fusion!
I haven't tweaked the settings yet to see if it's playable but I'm hopeful.
VMware, you are amazing!
UPDATE: I played LOTRO for a little bit tonight. I had to turn sound off as it was too jittery. Graphics were fine, though, on Low detail and low resolution. The mouse look problem mentioned in the comments was easily fixed by just going to options and changing the mouse look sensitivity.
by : Created on May 6, 2008 : Last modified May 6, 2008 : (permalink)
Reusable Django Apps And Introducing Tabula Rasa
The excellent 42 Topics blog has a post entitled Popularizing Django — Or Reusable apps considered harmful which makes (or attempts to make) the case for packaged apps over reusable apps.
He raises some good points, although of course the packaged apps he's talking about still use reusable apps so he's not actually talking about there being a problem with reusable apps per se, just that there should be packaged apps as well.
I mentioned the django-hotclub group in a comment on that post as I'd really like the discussion to take place there.
I also, in that comment, mention something I'm working on tentatively called Tabula Rasa. (I'm toying with a Greek name rather than Latin but something tells me people are more comfortable with tabula rather than grammateion)
Basically, the goal of Tabula Rasa is an out-of-the-box Django-based website with everything but the domain-specific functionality.
So far it's just my new django-email-confirmation app tied together with password change and reset, login/logout, with the beginnings of a tab-style UI. There's a ton more I want to refactor out of my existing websites to put into it as well as adding support for OpenID and the stuff I'm starting to do for django-friends.
Even if one doesn't use Tabula Rasa as the starting point of a website, I'm hoping it will prove very useful for another goal, namely a "host" project to develop and tryout reusable apps.
One of the challenges I know I've always had with writing or trying out reusable apps is the need for a project to provide the scaffolding.
So Tabula Rasa will hopefully serve that dual purpose.
UPDATE: I've decided to switch to the Greek word pinax suggested below by Orestis Markou.
UPDATE 2: Now see Introducing Pinax.
by : Created on May 6, 2008 : Last modified May 9, 2008 : (permalink)
Metrics As Mappings Between Arrows and Stacks
Another post for the Poincaré Project.
Back in Coordinate Systems and Metrics we saw that a metric for a coordinate system tells us the "distance travelled as proportion of coordinate change". Then in the following post, Metrics in Two or More Dimensions:
Imagine that you're at a particular point on a two-dimensional manifold. If you head off in a particular direction from that point at a particular rate, your coordinates will change. The metric tells you, from a given point, the rate of change of each of your coordinates given travel in a particular direction at a particular rate.
Those two posts express two sides of the same coin: in one I said the metric tells us the rate of change of position given the rate of change of coordinates and in the other I said the metric tells us the rate of change of coordinates given a rate of change of position.
A rate of change of position is, as we've seen, an arrow-vector. A rate of change of a particular coordinate is, as we've also seen, a stack-vector in the dual space.
In fact, one can view a metric as being a mapping between arrow-vectors and stack-vectors. You can use it, along with some calculus if the metric is different at different points, to calculate distances (as described in Coordinate Systems and Metrics). It can also be used to calculate the length of a vector or the angle between two vectors (concepts which don't exist without a metric).
A metric ties those length and angle notions to the coordinate system and, in so doing, actually defines the coordinate system.
Finally, a metric has within it, all the information necessary to describe the curvature of a manifold. It is ultimately this function that makes it relevant to both the General Theory of Relativity and the Poincaré Conjecture.
We will explore each of these in due course. The main takeaway at this point is that a metric is a mapping between arrow-vectors and stack-vectors.
by : Created on May 4, 2008 : Last modified May 4, 2008 : (permalink)
Factoring Out Common Args To Zipped Generators
I'm playing around with some additive synthesis in Python.
I've implemented an oscillator as a generator that takes a number of parameters. It is then possible to mix multiple oscillators using zip (or better, itertools.izip) over them and doing a (weighted) sum.
However, I wanted to be able to factor out common arguments to the oscillators so I didn't have to specify the frequency of each one individually.
I knew functools.partial would be part of the solution but it took me a while to work out how to combine its use with generators and itertools.izip.
Here is a simplified progression of what I came up with.
Phase 1
Rather than use oscillators, let's just imagine with have a generator that works a lot like xrange:
def gen1(start, stop, step): n = start while n <= stop: yield n n += step
then we can combine multiple generators and, say, sum the corresponding elements like this:
for x in zip(gen1(10, 20, 2), gen1(10, 25, 3)): print sum(x),
Phase 2
Let's abstract this into a function that takes generators as arguments (and uses itertools.izip)
def mixer1(*generators): return (sum(x) for x in izip(*generators))
for x in mixer1(gen1(10, 20, 2), gen1(10, 25, 3)): print x,
mixer1 is similar to my mixer (although without weighting)
Phase 3
But now say we wanted to factor out the common start parameter. First we need a partial version of function gen1:
gen2 = lambda **kwargs: partial(gen1, **kwargs)
This allows one to say
partial_gen = gen2(stop=20, step=2)
and then later call
partial_gen(start=10)
to get the generator.
But what we now need is a new version of the mixer that takes the extra keyword args and passes them in to each partial function to turn them back into generators:
def mixer2(*generators, **kwargs): return mixer1(*[gen(**kwargs) for gen in generators])
and now we can say:
for x in mixer2(gen2(stop=20, step=2), gen2(stop=25, step=3), start=10): print x,
Phase 4
Here's the final version:
gen2 = lambda **kwargs: partial(gen1, **kwargs)
def mixer3(*generators, **kwargs): return (sum(x) for x in izip(*[gen(**kwargs) for gen in generators]))
The real thing is a little more involved because of the weighted summing, etc but the hard parts are shown.
by : Created on May 2, 2008 : Last modified May 3, 2008 : (permalink)
Moiré Waves
I was playing around with some additive synthesis in Python, generating various basic waveforms and checking them visually, in Soundtrack Pro.
The moiré pattern of the waveforms in one test file was interesting:

That's actually 220 cycles of a sine wave, followed by the same for a sawtooth, square and triangle waveform.
by : Created on May 1, 2008 : Last modified May 1, 2008 : (permalink)
Grammar Rules
One downside to having a background in linguistics is that one is more sensitive to various so-called grammar rules that people regurgitate from their school years.
The majority of linguists probably view these rules the way a doctor would view the four humours. But a more fundamental issue is not that some of the theories have been superseded but that their perpetuation reveals a very unscientific approach to language. It is as if these people are viewing rules of grammar like they would road rules—human inventions that one may disagree with, but which are still, in some sense, what is "correct"—rather than, say, laws of physics that attempt to model observations.
This means that when confronted with data that doesn't match the rules, such people will say the data is wrong ("that isn't correct English") rather than ever consider that maybe it's their rules that need refinement.
Now it is certainly the case that people make mistakes when they speak (and that can be a revealing study in itself) and there is such a thing as good English usage (see the last paragraph) but most linguists focus on modeling the tacit intuitions native speakers have about their language which are very often at odds with the "rules of grammar" learnt at school.
Let me give an example. A common misconception is that English has cases that work in a similar way to Latin. I suspect the origins of this stem from attempts to model English after Latin as if Latin was somehow a better language.
It is easy to see on the surface there might be evidence for a nominative/accusative case distinction in English pronouns. Native speakers will say "I gave the book to him. He gave the money to me." with the intuition that switching "I" and "me" or "he" and "him" would be incorrect. This is a valid observation that a linguist would want to capture in some kind of descriptive rule.
However, when asked "who is it?" native speakers will almost always answer "it's me" rather than "?it's I".
I've had people try to tell me that the latter is "more correct" although they don't say it themselves. If they don't say it, as competent speakers of English, what is their claim to it being correct? Because their high school English teacher told them? Because Latin would use the nominative here?
If you ask a group of people "who wants to sit in the front?" they are far more likely to answer "me" than "?I". And yet they would say "I do" rather than "*me do". If you accuse someone you are probably more likely to say "it was him" not "?it was he". So what's going on doesn't just involve using the nominative case for the subject and accusative case for the object.
The massive 1,800+ page Cambridge Grammar of the English Language gives more great examples "nobody can do it but her/*she", "the only one who objected was me/?I" and (showing photos) "this one here is me/*I at the age of 12".
Things become even more complex in the case of conjunctions. The Cambridge Grammar gives the example of "they invited my partner and I to lunch". They point out that examples like this "are regularly used by a significant proportion of speakers of Standard English, and not generally thought by ordinary speakers to be non-standard". They go on to argue against the prescriptivist use of analogy with "they invited me/*I to lunch" to justify why the use of "I" is incorrect.
The worst kinds of rules are ones that sound almost like superstitions: don't use passives, don't use adverbs, don't split infinitives, don't end sentences with a preposition, don't start a sentence with "however" etc. They may help one adopt a particular style of writing, but they certainly aren't rules of grammar in any scientific sense and are, in most cases, completely arbitrary.
Some of the usage guides these rules are found in are better than others. Strunk and White is full of these arbitrary superstitions. In fact, Professor Geoffrey Pullum, the co-editor of the previously mentioned Cambridge Grammar of the English Language describes Strunk and White as a "horrid little notebook of nonsense" and instead recommends Merriam-Webster's Concise Dictionary of English Usage which I own and agree is much more useful for evidence-based guidelines on subtle differences in usage between words.
by : Created on May 1, 2008 : Last modified May 1, 2008 : (permalink)
UPS Invents Time Travel

and who is BERT in Provo?
by : Created on April 30, 2008 : Last modified April 30, 2008 : (permalink)
Why Colour Correction Only Needs Two Sliders
Duncan Davidson (who I still think of as James) asked on Twitter:
Color Temp works on the Blue/Yellow axis. Tint on the Green/Magenta. No need to tweak Red/Cyan?
I responded there but decided to here as well as I've talked about colour theory before.
The basic answer is that you only need two axes because colour (disregarding brightness/luminance) is two-dimensional. Red, Green and Blue form a triangle in that two-dimensional space (with Cyan, Magenta and Yellow being on the opposite edges respectively).
Basic linear algebra tells us that, in an n-dimensional space, you only need n vectors to form a basis (actually, that's the definition of dimensionality) so you can adjust any point in two-dimensional colour space by translating it by a linear combination of any two, non-parallel vectors. Incidentally, Hue and Saturation would be almost polar coordinates on this space.
Because one form of colour modification is colour temperature, it makes sense to roughly make one of the axes the yellow-blue direction. I think the magenta-green axes is largely arbitrary. Any other axis would have done fine.
Note I say "roughly" the first time in that previous paragraph because the black-body colours aren't a straight line in standard colour models.
Hmm, that makes me wonder if colour correction sliders represent rectilinear bases at all.
UPDATE (2008-05-04): According to a reply in the Reddit thread, the slides aren't rectilinear but are based on the black-body colours. The so-called "tint" is presumably then orthogonal to black-body line (the Planckian locus)
by : Created on April 29, 2008 : Last modified May 5, 2008 : (permalink)
Auto-Scrolling in jQuery
I mentioned in my previous post New Site Look that, inspired by 37 Signals, I wanted to auto-scroll pages in my website in two circumstances:
- when there is an error in an Add Comment form, scroll down to the error message
- when the user expands the Add Comment form, scroll to put the form in view
Here's the fragment of my Django template that achieves both of these with jQuery:
<script type="text/javascript" src="/static/jquery.js"></script> <script type="text/javascript"> function scrollTo(selector) { var targetOffset = $(selector).offset().top; $('html,body').animate({scrollTop: targetOffset}, 500); } $(document).ready(function() { $('#add_comment_toggle').click(function() { $('form.add_comment').slideToggle(); scrollTo('form.add_comment'); return false; }); {% if comment_error %} $('form.add_comment').show(); scrollTo('.comment_error'); {% endif %} }); </script>
The only bit of Django, for those who don't know it, is the {% if ... %} which only includes that Javascript if a comment_error exists.
The scrollTo function scrolls to the element whose selector is given. Notice how, if a comment_error exists, I make sure the form is showing first, then call scrollTo.
Also, in my code for toggling the Add Comment form, I call the function to scroll to the form.
by : Created on April 28, 2008 : Last modified April 28, 2008 : (permalink)
New Site Look
If you read this in a feed reader, you might want to go to my actual site to see what I'm talking about :-)
Usually, when I rewrite the underlying code behind jtauber.com, I do a redesign of the look as well. In the 14 years that jtauber.com has been around, it's probably had around 10 different looks. The last change took place when I wrote Leonardo in 2003.
When I ported Leonardo to Django I really should have changed the look, in keeping with tradition, but I didn't. I decided this weekend to do some code clean up and add a couple of new features and ended up doing a completely new look as well. I also switched from Django 0.96.1 to Django trunk (including qs-rf), although I don't make use of any of the new features yet.
Here's a brief list of what I did change:
- changed colour from the green I've had for the last five years to a purple more like what I had in 2002 but with lickable gradient site title
- went from a two-column to three-column layout so I'd have a place to put some Web 2.0 goodies on every page
- added my photo to the home page :-)
- added Twitter updates
- added links to my Facebook and LinkedIn profiles
- added an overflow property to pre so code examples don't overlap the right column
- fixed an annoying bug where if you got the maths question wrong your comment would get forgotten
- made add comment form initially hidden and available only via a toggle
- inspired by this video at 37 Signals, I added some auto-scrolling to the add comment form—when there is an error in submission, the page automatically scrolls to the errors; and when you toggle the comment form open, it automatically scrolls so the form is fully in view.
Had to trigger hasLayout in IE6 to get it to work there. Fortunately, I'd had that issue previously with Quisition so knew what to do. Thank goodness for VMware Fusion to enable me to check the site on IE6.
I quite like the new look, especially in comparison to the old look. I'm more than a little chuffed at getting the autoscrolling working too :-)
by : Created on April 27, 2008 : Last modified April 27, 2008 : (permalink)
django-email-confirmation
This simple django app is for cases where you don't want to require an email address to signup on your website but you do still want to ask for an email address and be able to confirm it for use in optional parts of your website.
A user can have zero or more email addresses linked to them. The user does not have to provide an email address on signup but, if they do, they are emailed with a link they must click on to confirm that the email address is theirs. A confirmation email can be resent at any time.
As of r22, what's on the trunk here should be usable but I welcome feedback on how to make it better. The source contains a working project that shows all the features of the app as well as providing useful code for your own project.
This code is based in part on django-registration and is essentially a replacement for it where your requirements are different.
http://code.google.com/p/django-email-confirmation/
by : Created on April 27, 2008 : Last modified April 27, 2008 : (permalink)
Barry and Frank
Continuing on from the previous Barry and Frank story...
Colin comes up to Barry and Frank and says "I've just tossed this coin 100 times and recorded the result each time in this notebook. What is the probability that toss number 37 was tails?". Frank thought for a moment and asked "can we study the notebook?" "Sure," Colin said.
Frank took the notebook and looked through it before declaring "well, 40 out of 100 tosses were tails, so the probability of toss number 37 having been tails is 0.4".
"I agree," said Barry, somewhat to the surprise of Frank. But Barry then took the notebook, turned to the appropriate entry and said "oh, the probability just changed to 1"
by : Created on April 17, 2008 : Last modified April 17, 2008 : (permalink)
Probability Thought of the Day
If I ever taught probability and statistics, this is the problem I'd put on the board the first lecture:
Colin comes up to Barry and Frank and says, "hey guys! I have a coin here which is biased but I won't tell you which way or by how much. What's the probability of the next toss being tails?". Barry replied, "given what we know, it is 0.5". Frank looked astonished. "How can you say 0.5? Given the coin is biased, that's the one probability we know it can't be." Who is right, Barry or Frank?
UPDATE: corrected "a tail" to "tails".
UPDATE 2: Eliezer Yudkowsky has a great post on exactly this scenario. He's way smarter than I, so go read him :-)
by : Created on April 13, 2008 : Last modified April 13, 2008 : (permalink)
History
via James Bennett and Bill de hÓra:
$ history | awk '{print $2}' | sort | uniq -c | sort -rn | head 120 cd 111 ls 78 python 73 svn 17 mate 14 less 11 rm 11 mv 7 mkdir 5 ssh
No surprises there at all :-)
by : Created on April 10, 2008 : Last modified April 10, 2008 : (permalink)
More About Twitter
On my previous entry about Twitter, Nelson commented:
I still don't really get what Twitter is... would it be useful to me?
I could describe Twitter as to blogging what IM is to email but that's not enough.
I admit that I didn't get Twitter at first. For months I just thought it wasn't my kind of thing.
Then something changed.
For me Facebook status was the gateway drug. Once I got interested in what people were doing, thinking, and responding to in their Facebook status, Twitter started to make more sense.
The other thing that changed was I built a critical mass of interesting people to follow. Some of them were people I only vaguely know but who I knew had interesting things to say. Some I confess are just fly-on-the-wall eavesdropping.
But the two most interesting categories are the friends who I can keep more in touch with about day-to-day stuff and the acquaintances (or strangers) with common interests who I strike up spontaneous conversations with.
Here is fun example last week. Someone mentioned that Game Neverending (GNE) was back. So I went and checked it out. It closed down a couple of hours later so I never would have known about it in time if not for Twitter. Later on in the week, I twittered that I'd like to write a GNE-clone in Django. As well as a number of people asking me what GNE was, I also had a reply from a guy I met at PyCon saying he'd love to be involved. So we worked on it together over the weekend (see my post about it. All this happened because of Twitter.
To build the critical mass of people to follow (what I did, anyway):
- if you're on Facebook, see which of your friends are twittering and start following them
- import your contacts (I did this via gmail even though I don't use gmail) to see other friends who twitter
- look at who your friends are following and start following some of those people
- look to see who your followers are replying to and start following them
- if someone follows you, check them out and, if they're not spam, follow them
The other thing that helped me get into it was finding a client app. I've used Twitterific and Twhirl and like both a lot.
Incidentally, I twittered that I was writing this post and immediately received a number of suggestions and links (thanks @moof and @epoz)
Suggested blog posts on this topic included:
- Nearly a million users, and no spam or trolls by Russell Beattie
- On Twitter by Tim Bray
I'll also twitter with a link to this post for people to add their comments to.
Will it be useful to you? If you like finding out what friends are up to; if you like learning about new things going on from smart people with common interests; if you like making serendipitous connections based on overheard conversations, then Twitter will be useful to you.
Hope this helps!
P.S. If you follow a lot of people, never be afraid to just ignore the river of tweets when you're busy (or sleeping). I generally don't look at Twitter at work, for example, and only rarely ever go back to skim what I missed.
UPDATE: Definitely watch the short video http://www.commoncraft.com/Twitter that David recommends below!
by : Created on April 7, 2008 : Last modified April 7, 2008 : (permalink)
Game Neverending in Django
In the early hours of April 2nd I heard via Twitter that Game Neverending, the online game that never launched but which gave rise to Flickr, had come back. I played it for about an hour and loved it but then had to go to work. When I got home, the game had been shut down again—I guess it was just an April Fool's joke.
Digging around I found the GNE museum which had a fair amount of information about the game mechanics. It occurred to me that it would be fairly straightforward to implement most of the concepts as a Django-based website.
So yesterday, I started django-mmo at Google Code Project Hosting. So far I've implemented the basic location system and support for some aspects of game items (player inventory, picking up and dropping, spawning but not the making system yet). I haven't paid any attention yet to UI (sort of looks like Web pages did in 1993) and the whole thing so far is played in a kind of "God-mode" where you can control any player. In a way, the UI is just there for testing the model at the moment.
But I'm making good progress. The initial goal is parity with GNE (or at least what I can glean from GNE museum) and then I can think about ways of extending it.
UPDATE (2008-04-13): Making and chat are now implemented. The UI is getting close to parity too.
by : Created on April 6, 2008 : Last modified April 14, 2008 : (permalink)
Twittering
I've been using Twitter a lot lately. My page is http://twitter.com/jtauber if you'd like to follow me.
I've also set up a Twitter account for Quisition and over the weekend plan to hook up notifications so that @quisition will tweet when there are new announcements and new packs.
And speaking of Quisition, I've created a Facebook page where I'll also post updates.
by : Created on April 4, 2008 : Last modified April 4, 2008 : (permalink)
April Fools
Best Joke I Fell For
Tim Ferriss announcing he's been outsourcing his blog writing the last year.
What was brilliant about this was that I felt duped even before I realised it was a joke. Then I felt double-duped :-)
Best Joke I Didn't Fall For
YouTube Rickrolling.
Read about it on TechCrunch before I went to YouTube (not that I look at the featured videos anyway).
Best Joke With Just A Touch Of "Maybe They Aren't Completely Joking"
Google and Virgin joining forces to colonize Mars.
Who knows what parts of this they may actually be planning?
by : Created on April 2, 2008 : Last modified April 2, 2008 : (permalink)
Thunks, Trampolines and Continuation Passing
Here is a thunk, a kind of delayed apply that takes a function and arguments but, rather than calling the function right away returns another function that, when called, will call the first function with the arguments originally given.
thunk = lambda name, *args: lambda: name(*args)
Here is a trampoline that basically unwraps nested thunks until a result is found.
def _trampoline(bouncer): while callable(bouncer): bouncer = bouncer() return bouncer
Here is a useful wrapper function that turns a function into a trampolined version.
trampoline = lambda f: lambda *args: _trampoline(f(*args))
Now let's just define one more ingredient, an identity function.
identity = lambda x: x
Now we can write factorial in continuation-passing style:
_factorial = lambda n, c=identity: c(1) if n == 0 else thunk(_factorial, n - 1, lambda result: thunk(c, n * result))
and trampoline it:
factorial = trampoline(_factorial)
We now have a factorial function that doesn't have stack limitations. You can say
print factorial(100000)
and (a couple of minutes later) Python will happily display the result :-)
I did consider currying thunk:
thunk = lambda name: lambda *args: lambda: name(*args)
so the CPS factorial would be:
_factorial = lambda n, c=identity: c(1) if n == 0 else thunk(_factorial)(n - 1, lambda result: thunk(c)(n * result))
UPDATE: Sorry to the first few commentors, due to a cute-and-paste SNAFU I was using the curried version of thunk for the first definition of _factorial. Now fixed.
by : Created on March 30, 2008 : Last modified March 30, 2008 : (permalink)
Coordinate Systems and Stack-Type Vectors
(on a bit of a roll with the Poincaré Project recently)
Back in 2006, I talked about the notion of a coordinate system which, for some region of a manifold, provides a tuple of real numbers identifying each point in that region. The mapping is homeomorphic so the coordinate system is continuous.
You can think of each component of the tuple as a separate function that maps from a point on the manifold to a real number. So, for a two-dimensional manifold, there's an x-coordinate function and a y-coordinate function that respectively tell you the x-coordinate and y-coordinate of a given point. The tuple for point p is then just (x(p), y(p)). The situation for a three-dimensional manifold is similar, you just need a third coordinate function. (Note these functions aren't inherent to the manifold, they are structure added to a manifold and you can, of course, have any number of alternative coordinate systems for the same region of a manifold.)
Each of these coordinate functions is no different than something like temperature or electric potential. They are all scalar fields—continuous real-valued functions on a region of a manifold—that give a real value for every point in that region in a way that if you traveled along a continuous path through the manifold, the value would change continuously.
Now say we wanted to describe how one of these coordinate functions changes as one moved in a particular direction from a particular point on the manifold. Well, we've already seen that
stack-type vectors are about rates of change of some quantity as position changes.
so you can actually think of a coordinate system as defining N stack-type vectors at every point, where N is the number of dimensions of the manifold. Just look at a piece of graph paper and you can see the stack-type vectors. Because the stack-type vectors are showing the rate of change of the coordinate, they are actually the derivative of the coordinate with respect to position (i.e. the gradient).
You can probably already see it, but something interesting happens when we combine the notion of traveling in a particular direction at a particular rate with the notion of a particular quantity (coordinate or otherwise) changing according to position. We'll talk about that next.
by : Created on March 28, 2008 : Last modified March 28, 2008 : (permalink)
The Rubik's Cube Can Be Solved But Is It Grammatical?
In my previous post I mentioned Joyner's paper Mathematics of the Rubik's Cube.
The phrase "The Rubik's Cube" sounds odd because you can't normally use an article with a pre-nominal genitive if the pre-nominal itself wouldn't normally take an article.
You can say "the paper", "the professor" and "the professor's paper". You can say "David's paper" but not "*the David's paper". (Although note that if talking about the sculpture "the David", you can say things like "the David's left hand". And, because of Donald Trump, you could say "the Donald's hair".)
You can't say "the Rubik" and so "the Rubik's cube" seems ungrammatical if you think about its component parts.
What's happening is, of course, that "Rubik's" isn't acting as a genitive anymore but rather "Rubik's Cube" has been reanalyzed as an opaque compound noun. It's just still written in terms of its components.
by : Created on March 27, 2008 : Last modified March 27, 2008 : (permalink)
Twenty-Five Moves Suffice
I've talked about the Rubik's Cube before and linked to last year's paper by Kunkle and Cooperman proving Twenty-Six Moves Suffice for Rubik’s Cube.
Now Tomas Rokicki has proved that Twenty-Five Moves Suffice for Rubik's Cube. Actually, what he proved is that no configuration takes 26. If x <= 26 and x != 26 then x <= 25 QED.
It is known that some configurations need 20 moves and that no configuration needs 21. So the possible optimal move maxima are 20, 22, 23, 24 and 25.
Via Dave Long, I also found out about Joyner's Mathematics of the Rubik's Cube (pdf) which became the book Adventures in Group Theory.
UPDATE: Actually, I don't think it's been proven that no configuration needs 21, just no configuration has been found that needs 21.
UPDATE 2: David Joyner informs me a 2nd edition of his book is coming out soon.
by : Created on March 27, 2008 : Last modified March 28, 2008 : (permalink)
First to Hit 100
So I was about to blog on the fact that in the last two hours I've read about both Opera and WebKit reaching 98/100 on the Acid 3 Test and that I was wondering who would hit 100/100 first.
Then I saw this ACID3: Strike ninety-eight. Make that 100
Congratulations!
UPDATE: WebKit is the first to make it public, though. Note, neither actually pass the full test yet (which requires pixel-accuracy with a reference image).
by : Created on March 26, 2008 : Last modified March 27, 2008 : (permalink)
Latin Mottos on Japanese Running Shoes
The name of Japanese athletic equipment company ASICS is an acronym for the Latin phrase anima sana in corpore sano—"a sound mind in a sound body".
by : Created on March 26, 2008 : Last modified March 26, 2008 : (permalink)
Documentation Can Speed Up Your Code
I just was documenting some code that looked (roughly) like this:
def a(x, m): for i, o in enumerate(sorted(x)): if o > m: break return i
and my comment was "return how many items in x are less than or equal to m".
The very act of writing the comment made me realise the code could be rewritten as:
def a(x, m): return len([o for o in x if o <= m])
which is not only more succinct but runs 6-8 times faster! (UPDATE: ...on my data size -- as Sergio points out below, the two algorithms differ in complexity)
(Incidentally, the list comprehension also runs twice as fast as the equivalent using filter)
UPDATE (2008-03-26): Fascinating discussion going on in the comments :-) Although still largely orthogonal to the main point which is that I was originally trying to solve a domain-specific problem and it was only when I went to comment the code that I realised that what I was really doing was trying to find how many items in a list are less than or equal to a certain number. How best to do that is a topic for...well, I guess the comment thread :-)
by : Created on March 25, 2008 : Last modified March 26, 2008 : (permalink)
One-Forms Form Linear Spaces
One of the important takeaways from arrows and stacks as duals is that
Every linear space has a dual space whose elements are the linear, scalar-valued functions on the original space.
These linear, scalar-valued functions have a number of different names. They are variously called linear functionals, linear forms or, more specifically, and as we will call them, one-forms.
For our purposes, the one-forms are real-valued (because our linear spaces are real), although in quantum mechanics I think dual spaces are always made of complex-valued functions (and complex linear spaces).
Let's just quickly demonstrate that the dual space is itself a linear space:
Firstly, by virtue of the fact the one-forms are linear, we know:
- w(kv) = k w(v)
- w(u + v) = w(u) + w(v)
We define addition of one-forms:
- (w+x)(v) = w(v) + x(v)
and scaling of one-forms:
- (k w)(v) = k w(v)
We can see that one-forms do form a linear space, just by the algebraic properties of real number addition and multiplication:
- ((w + x) + y)(v) = (w(v) + x(v)) + y(v) = w(v) + (x(v) + y(v)) = (w + (x + y))(v)
- (w + x)(v) = w(v) + x(v) = x(v) + w(v) = (x + w)(v)
- there is an additive identity 0 which simply maps every vector to 0.
- for every w there is an additive inverse -w such that (w + -w)(v) = w(v) + -w(v) = w(v) - w(v) = 0 = 0(v)
- a (w + x)(v) = a ( w(v) + x(v) ) = a w(v) + a x(v)
- (a + b) w(v) = a w(v) + b w(v)
- a (b w(v)) = (ab) w(v)
- 1 w(v) = w(v)
Remember that if we view vectors in the context of a manifold as arrows, the corresponding one-forms are stacks.
In matrix algebra, column vectors and row vectors are similarly duals of one another.
In the next entry, we'll look at the relationship between one-forms and coordinate systems.
by : Created on March 23, 2008 : Last modified March 23, 2008 : (permalink)
Graded Reader Discussion and Code
Owing to the amount of interest I received about A New Kind of Graded Reader,
I have started a mailing list at
http://groups.google.com/group/graded-reader
and also I plan to make my code available at
http://code.google.com/p/graded-reader/
If you're interested in the idea applied to any language (not just NT Greek) please join us.
by : Created on March 22, 2008 : Last modified March 22, 2008 : (permalink)
Arrows and Stacks as Duals
Part of the glacial Poinaré Project.
We've introduced the notion of a linear space and seen that, in the context of a manifold, there are at least two distinct types of linear spaces:
Arrow-type linear spaces are about position on the manifold and rates of change of position. Stack-type linear spaces, on the other hand, are about rates of change of some other quantity defined on the manifold as position changes.
These two types of linear spaces have a special relationship to one another. An arrow-type vector and a stack-type vector can be multiplied together to give a quantity which has no reference to distance or direction (what is called a scalar) and which is immune to transformations that maintain the topology of the manifold. Geometrically, you can calculate this quantity by counting how many "stacks" of the stack-type vector the arrow-type vector passes through.
Because this operation of multiplying arrow-type and stack-type vectors doesn't require any additional structures and is preserved under a homeomorphism, is it more fundamental than, say, the inner (or dot) product. As we will see in the next couple of entries, though, it has a relationship to the inner product, mediated through the metric.
We can go one step further and, algebraically, think of a stack-type vector as a function that turns arrow-type vectors into scalars. In other words if V is an arrow-type linear space then a particular stack-type vector w can be thought of as a function w: V -> R. Because the stack-type vectors that apply to the arrow-type vectors in V follow the axioms of linear spaces, the following rules fall out:
- w(kv) = k w(v)
- w(u + v) = w(u) + w(v)
Or put more succinctly, w is a linear, real-valued function on V.
Because the linear space of stack-vectors that apply to V has a special relationship to V, it is said to be the dual of V.
It is worth noting that everything above still works if you swap arrows and stacks. In other words, you can view arrow-type vectors as linear, real-valued functions on the linear space of stack-type vectors. The dual relationship is symmetrical. In fact, the only thing that makes one "arrow-type" and the other "stack-type" is their relationship to a manifold.
You can talk about a linear space and its dual without reference to an underlying manifold on which the vectors live. For example, the n-tuple space has a dual as well. For a given linear space of n-tuples, this dual space is the space of all linear, real-valued functions on those n-tuples.
by : Created on March 22, 2008 : Last modified March 22, 2008 : (permalink)
Another You Me Us We Review
Forte Magazine has a review of Nelson Clemente's EP and had this to say about You Me Us We (which I composed and co-produced):
Aussie boy Nelson Clemente has been impressing blogger types for most of 2007; his ace track "You Me Us We" left a mark on many electronic music fans with its subtle throwbacks to mellow house and 80’s europop. Its gorgeous harmony, solid production and heart-tugging lyrics helped the track along in earning its title as EQ’s Song Of The Year, 2007. Nelson’s debut E.P. "6th Perception" features this pop masterpiece along with several remixes and two new tracks.
and later...
For a first E.P (three tracks, four remixes,) this is a solid start. The perfect and sublime "You Me Us We" is still the best song on here.
Emphasis mine :-)
by : Created on March 21, 2008 : Last modified March 21, 2008 : (permalink)
Relatively Speaking
Special Relativity uses straightforward mathematics with mind-bending physical implications. General Relativity uses mind-bending mathematics with straightforward physical implications.
Or so I described it to someone at PyCon tonight.
by : Created on March 19, 2008 : Last modified March 19, 2008 : (permalink)
Inconsistent Symlinks
Set up directories as follows:
drwxr-xr-x 2 jtauber staff 68 Mar 18 17:57 A drwxr-xr-x 3 jtauber staff 102 Mar 18 17:58 B lrwxr-xr-x 1 jtauber staff 3 Mar 18 17:58 C -> B/C
Now cd into B
jtmbp:TEST jtauber$ cd B
If you try to "execute" A from here, it tells you it's a directory
jtmbp:B jtauber$ ../A -bash: ../A: is a directory
Now go back to the top directory
jtmbp:B jtauber$ cd ..
and cd into C (the symlinked directory)
jtmbp:TEST jtauber$ cd C
If you try to execute A from here, it can't find it via "../A" only "../../A"
jtmbp:C jtauber$ ../A -bash: ../A: No such file or directory jtmbp:C jtauber$ ../../A -bash: ../../A: is a directory
so the attempt at execution is based on the actual absolute path, not the path based on following the symlink.
However,
jtmbp:C jtauber$ cd ../A jtmbp:A jtauber$
So cd uses the path based on following the symlink but relative paths for execution do not.
I realise this is likely because cd is shell-based (and so knows the path that was followed to get to the current directory) whereas execution is a system call (which doesn't know the path that was followed to get to the current directory) but it's interesting nevertheless (and occasionally annoying).
This is on OS X but the behaviour is the same on Linux as far as I know.
by : Created on March 18, 2008 : Last modified March 18, 2008 : (permalink)
PyCon Update
I am proud to announce that a couple of hours ago, I was elected to both membership and to the board of directors of the Python Software Foundation. Thank you to David Goodger for nominating me for membership and for encouraging me to run for the board again.
It's a nice coincidence that it happened on Pi Day.
This afternoon at PyCon I'm looking forward to some exciting Django news from Adrian.
Tonight we're running a BOF for anyone interested in mentoring Python projects in the Google Summer of Code.
Note: the last twenty minutes has been the longest I've had a working network connection since I got here :-(
UPDATE: It was actually Jacob that made the announcement. I don't want to steal his blog thunder so I won't mention it here other than to say, it's something I want to help out with :-) Very exciting!
by : Created on March 14, 2008 : Last modified March 14, 2008 : (permalink)
PyCon
On Wednesday, I'll be heading to Chicago for PyCon. I'm looking forward to catching up with people there and getting a lot of Django hacking done.
by : Created on March 11, 2008 : Last modified March 11, 2008 : (permalink)
I Have A Song On iTunes
I have a song on iTunes!
Previously, I've written about my song You Me Us We which was a finalist in the Unisong International Songwriting Contest and named by ElectroQueer as their Number One Song for 2007.
Well, now Nelson Clemente's debut EP 6th Perception, which features the song, is available on iTunes!
BUY THE ALBUM! Or at least buy the song :-) It's track number 3.
by : Created on March 1, 2008 : Last modified March 1, 2008 : (permalink)
Google Summer of Code 2008
Well, the Google Summer of Code is on again and the Python Software Foundation have asked me to coordinate for the second year (mustn't have screwed up enough last year :-)
It's early days (the organizations involved haven't even been picked yet) but if you are interested in participating in a Python project, either as a mentor or student, you should check out both the official Google page and the SummerOfCode page on the Python wiki.
You should also join the soc2008-general mailing list.
by : Created on Feb. 27, 2008 : Last modified Feb. 27, 2008 : (permalink)
Another Dictionary Trick
Continuing on from my previous post about python dictionaries.
Imagine you're using a defaultdict to count objects. That is, you set up like this:
from collections import defaultdict counts = defaultdict(int)
and then have a bunch of these for different keys:
counts[key] += 1
Now say you want a list of all the objects in order of their count, like I did earlier this morning. My first intuition was to use
sorted(counts, key=lambda i: counts[i])
which then got me wondering if there was a way to create a function that gets an item from dictionary without using lambda—much the same way as the operator module can be used instead of lambdas in many cases.
Then I had a doh! moment. Of course there's a function that gets an item from a dictionary: the get method. And so the above can be rewritten:
sorted(counts, key=counts.get)
by : Created on Feb. 27, 2008 : Last modified Feb. 27, 2008 : (permalink)
Evolution of Default Dictionaries in Python
I write a lot of code where I use a dictionary of sets (or lists or counters, etc)
Method 1
dict_set = {}
if key not in dict_set:
dict_set[key] = set()
dict_set[key].add(item)
Method 2
dict_set = {}
dict_set.setdefault(key, set()).add(item)
Method 3
from collections import defaultdict dict_set = defaultdict(set) dict_set[key].add(item)
setdefault was added in Python 2.0 and I've been using (and loving) it for years.
It was only a month or two ago that I discovered collections.defaultdict. Now I use it almost every day.
UPDATE: I forgot to mention that defaultdict was added in Python 2.5. And owing to the fact that int() returns 0 you can use defaultdict(int) for a dictionary of counters.
by : Created on Feb. 27, 2008 : Last modified Feb. 27, 2008 : (permalink)
Time Machine Isn't What It Used to Be
Yesterday, after a mammoth session importing and organizing photos in Aperture 2, Time Machine informed me that the backup drive was full.
That didn't bother me—it was inevitable—but what did disturb me was the rest of the message. It told me that the earliest backup was now February 18th. In other words, it had eliminated everything from November 19th thru February 17th.
I knew what the behaviour would be when the disk filled up but I didn't expect it to eliminate so much in one go.
I suspect that I would be more likely to want to find stuff from November to February than in the last week although maybe I'm thinking of Time Machine too much as version control rather than backup. Still, I would have preferred it to sacrifice more recent backups rather than eliminate the oldest stuff.
There is an option "Warn when old backups are deleted" in System Preferences which was checked but I'm not sure if that means "tell me when old backups have been deleted" or "tell me when old backups are about to be deleted". My recollection of the message yesterday was that it had already done the deed and there wasn't anything I could have done about it.
Either way, I wish the behaviour in this scenario had been different.
by : Created on Feb. 24, 2008 : Last modified Feb. 24, 2008 : (permalink)
Script Breakdown
This weekend, I'm trying to finish an initial breakdown of the script for In the Light of Day. As a preliminary step to scheduling and budgeting, a script breakdown means going through the script and identifying the locations, characters, props, etc, for each scene.
Because the script jumps around a bit, I'm actually distinguishing a scene as written in the script from a "story scene". I'm calling it a story scene if it's a single sequence of action in one location, even if it's non-contiguous in the script. The important point being that we almost certainly want to film a story scene in one go for continuity.
So the main relationships I'm dealing with are the many-to-one from script scene to story scene and the many-to-one from story scene to story location. (Again, I say "story location" because the same physical location may act for multiple locations in the story and I'm just focused on the locations in the story at this stage.)
Once that's done, the many-to-many relationship between characters and scenes can be added. And then from this, we can see who is needed in what locations for how long. And thus begins the process of scheduling (which I'll talk about when we get to it)
I have 98 script scenes and will report shortly on how many story scenes and story locations that corresponds to.
Incidentally, I'm doing all this in a home-grown Django app I'm building as I go along. Mostly just working in the admin console at the moment.
UPDATE (2008-02-17): After an initial pass, there are 75 story scenes and 24 story locations.
by : Created on Feb. 16, 2008 : Last modified Feb. 17, 2008 : (permalink)
A New Kind of Graded Reader
Back in 2004, I talked about algorithms for optimal vocabulary ordering. Then in 2006, I talked about using this and other techniques in teaching New Testament Greek (which I've resumed doing with this method, btw)
Earlier this year at BibleTech:2008 I briefly touched on my graded reader approach. It generated a lot of interest so I decided to record a separate presentation at home this weekend, explaining some of the ideas behind the graded reader.
After multiple failed attempts to upload it to Google Video, it's now on YouTube and embedded below. Sound was recorded and mixed in Logic Pro and then synchronized with a presentation in Keynote and output as Quicktime.
Running time is just shy of 9 minutes.
UPDATE 2008-03-22: I have started a mailing list at http://groups.google.com/group/graded-reader and also I plan to make my code available at http://code.google.com/p/graded-reader/
by : Created on Feb. 10, 2008 : Last modified March 22, 2008 : (permalink)
JMW's Strange Meeting With Romeo and Juliet
Back in the late 1980s there was a new music group in Perth called EVOS. In my final year of high school, I was involved with the EVOS Youth Ensemble as their youngest composer. I had an opportunity to have one of my pieces performed on the national classical radio station ABC FM during New Music Week when EVOS put on a concert featuring young Perth composers and performers.
One of the pieces performed that night was not composed by a local but by an obscure contemporary Hungarian composer, István Márta, that the leader of EVOS had met while studying in Hungary. The piece was entitled "JMW's Strange Meeting With Romeo and Juliet".
It was a playful piece, part minimalist, part neo-classical, part fugue with awesome time signature changes and scored for piano or harpsichord and 5 unspecified instruments. A New York Times review of the piece from the same time period described it as "a light, appealingly textured Minimalist interlude."
At various times during the last 17 years, I've wondered about getting hold of the score. About six months ago, I started looking online again and couldn't find it on any of the usual sheet music sites. I did see it on one sheet music distributor's catalogue but they didn't have any online ordering so I wrote to them. They told me they could order it especially from Hungary for me.
I'd given up on receiving it when yesterday, a package arrived containing the score. Just reading it brought back a flood of memories. But then last night, I realised about 80% of it in Logic Pro, pretty much using the instrumentation I remembered from the EVOS concert: piano, clarinet, sax, bass guitar.
When I'm finished, I'll put up an MP3 of it. I might also do a more electronic realisation of it (I'm thinking harpsichord + Moog).
UPDATE (2008-02-10): Here's an MP3 of my first realisation: piano, flute, soprano sax, clarinet, bassoon, acoustic guitar, bass guitar and percussion. Enjoy!
by : Created on Feb. 7, 2008 : Last modified Feb. 10, 2008 : (permalink)
Django Collaborator Wanted
Just on the off-chance I find the right match amongst the readers of this blog...
So here's the deal: I'd really like a django developer to collaborate with on Quisition, habitualist and/or one or two other sites I haven't announced yet. This isn't a paid gig (yet!), I'm looking for a partner or two. Also, and maybe this will make it more interesting for some of you: I want to make large parts of all my sites into generic open source django apps so you could view this as mostly contributing to a set of open source projects, but ones that are directed toward the needs of specific websites.
Other technologies involved are jQuery and PostgreSQL (and obviously Javascript, SQL, CSS and Python in general).
Being local (i.e. Boston area) would be preferred as I'd love time face-to-face but I'm open to remote collaboration. If we already know each other, that makes it a much easier decision.
Email me if you're interested in discussing more.
by : Created on Feb. 5, 2008 : Last modified Feb. 5, 2008 : (permalink)
Usavich
(via Ned Batchelder)
Usavich has to be just about the strangest thing I've ever seen. And yet I'm addicted.
I can't summarize this minute-or-two-per-episode Japanese cartoon any better than Ned does:
two rabbits are imprisoned in Russian jail. One is dumb and gentle, the other is placid unless provoked, and then he becomes ultraviolent. There's also a transvestite chick and a frog, and there's no dialog.
The first episode is weird. And it gets weirder after that.
The animation technique is fascinating, mostly 2D (in a style resembling a children's book) but with the occasional shift (especially in the second season) into the third.
And the series involves the most bizarre use of Bach's Jesu, Joy of Man's Desiring I've ever heard.
Also check out the Wikipedia page on Usavich.
by : Created on Feb. 4, 2008 : Last modified Feb. 4, 2008 : (permalink)
Statistics
Following Bob, Joe and Ryan, here are my Browser / OS stats for the last month (rounded to nearest tenth of a percent):
| Firefox | 54.6% |
| Internet Explorer | 24.7% |
| Safari | 9.9% |
| Mozilla | 6.5% |
| Opera | 2.5% |
| Windows | 60.3% |
| Linux | 20.5% |
| Macintosh | 18.3% |
(iPhone at 0.2%)
For comparison, here are the figures for the same period a year ago:
| Firefox | 44.8% |
| Internet Explorer | 37.1% |
| Safari | 9.6% |
| Opera | 3.4% |
| Mozilla | 2.21% |
| Windows | 69.4% |
| Macintosh | 16.9% |
| Linux | 12.9% |
by : Created on Jan. 30, 2008 : Last modified Jan. 30, 2008 : (permalink)
Marcie Lascher
For a while now, Marcie Lascher has been asking me to write a blog entry about her. She doesn't care what I say, she just wants to have a blog mention her so she feels more Web 2.0 enabled. But while I'm at it: Marcie, I think you are awesome!
by : Created on Jan. 22, 2008 : Last modified Jan. 22, 2008 : (permalink)
Macworld Keynote
Lots of good stuff of great interest to me.
No wow moments during the video given rumours and spoilers beforehand, although I did like the way he announced the studios behind iTunes movie rentals, announcing the mini-majors before the majors and the latter with the line "and by the way...these six too".
I've already bought external drives for use with Time Machine and already have an Airport Extreme, so Time Capsule came a little too late for me. It is a pain unplugging the drive from my laptop all the time, though. And if I get an Air (see below) I'd need a Time Capsule anyway; unless they release an update that allows any external drive to connect to an Airport Extreme.
I've already updated my iPhone. Ability to put bookmarks on the home page is nice (currently, I have Facebook and Quisition). I've tried out the locator and it works great in my apartment. I'll try it more tonight when I'm out on the road.
Updated iTunes too and rented a movie. Worked beautifully. I will definitely be watching a lot of movies this way now.
I don't have a TV here in the US (watch everything on my computer) so Apple TV doesn't interest me at the moment. Steve's admission of failure on the first release was refreshing and it's nice that Take 2 is a free software upgrade for existing Apple TV users.
I only heard Steve say "Boom!" once (around the 45m mark). Coincidentally, it was shortly after the Flickr demo blew up.
The Air is very appealing to me. I used to have a 12" PowerBook from 2004 when I was traveling between Australia and the US a lot. My current laptop (a 17" MacBook Pro I bought mid-2006) dates from a time when I was living for months at a time in a hotel and it was basically my primary machine. Now I've settled into an apartment, I have a Mac Pro as my primary machine. The times I do travel, the 17" is just a little too big.
So the Air is a nice option as a travel laptop. The battery life is appealing. I haven't heard anything about whether the SSD increases the battery life even more. The HDD is slow but the SSD is a lot more expensive. I haven't decided yet. I'm at least going to wait a couple of weeks to see one in person and hear initial feedback.
by : Created on Jan. 16, 2008 : Last modified Jan. 16, 2008 : (permalink)
Keynote Bad Request
Yet again I can't watch the Macworld Keynote Address Quicktime because of a "Bad Request" error. Has happened every year and I have to wait a day or two. What's a fanboy to do?
UPDATE: Working now.
by : Created on Jan. 15, 2008 : Last modified Jan. 15, 2008 : (permalink)
Quisition User Goals for 2008
Last year my goal for Quisition was to hit 1,000 users.
My goal this year is much more ambitious. It is to have 1,000 active users. To put that in perspective, with current rates of engagement (prior to the redesign, anyway) that would mean attracting 50,000-100,000 users.
That might be possible with $100k of AdWord spending, but I don't want to do that.
So the primary sub-goal is to raise the engagement rate from 1-2% to 5%-10%. More on that over the next few months (bottom line: improving functionality to make Quisition a more effective—and hence compelling—learning tool)
That still means I need to attract 10,000-20,000 users. Or 10-20x what I had at the end of last year. That's still a sizable increase in advertising costs, all other things being equal. Too rich for my blood.
I can reduce the CPC (cost-per-click) with better ads in cheaper placements. But the more important metric is the cost-per-conversion—how much does it cost to get a new user. Lower CPC doesn't matter if it doesn't result in a new user. Also, I can't think of a way of tracking where the long-term users came from so the thing I need to watch out for is that the cheapest conversions may not be the ones that last.
A more general notion, that applies regardless of whether the traffic source is an ad or, say, this blog, is how many people that visit the site actually sign up for an account. Before the redesign, that number was 5.6%. The redesign seems to be working already because that number is now 8.2%.
Just for the record, last year I was getting a 0.24% CTR (click-thru-rate) on my ads and 6% conversion rate. So far this year, I've increased the CTR to 0.3% and, since the redesign am getting a conversion rate of 10% from ad click-thrus.
So, to achieve 10,000-20,000 users, I need to:
- increase my ad budget
- decrease my cost-per-conversion
where the latter involves me trying to:
- decrease CPC with better ads in cheaper placements
- increase the sign-up rate of people coming to the site by both improving the functionality of the site and better promoting that functionality
The product of all those factors needs to be in the 10-20 range.
Of course, that all assumes that AdWords continues to be the biggest source of leads. I probably need to pursue other forms of promotion, but I really don't have any experience with that other than this blog.
by : Created on Jan. 14, 2008 : Last modified Jan. 14, 2008 : (permalink)
BibleTech 2008
I don't think I've mentioned it here before but next week, I'm one of the keynote speakers at the BibleTech 2008 conference in Seattle. While I've given talks a number of times about my Greek linguistics research, this will be the first time that I'll get to talk about how I've used technology in that research.
I plan to give a history of the MorphGNT project and the various sub-projects I've worked on over the last fifteen years, covering the evolution of data models, text encoding, tool sets and more. I then want to talk about the opportunities that lie ahead and where I hope the work will go in the future, particularly given my collaboration with Ulrik Sandborg-Petersen.
by : Created on Jan. 14, 2008 : Last modified Jan. 14, 2008 : (permalink)
Quisition Gets a Shiny New Look
I decided it was time for a redesign of the Quisition site. I started with the logo and things just took off from there.
I wanted to make the logo more modern and "lickable" and I found a really easy way to do it.
I started with the old logo, flat black text, Gil Sans Bold with a bit of kerning. Then I simply overlaid on top of the text an ellipse about as high as the text and maybe 50% wider, shifted up so that the bottom of the ellipse was roughly in the middle of the text. I then put a gradient fill on the ellipse: all white but varying in opacity from 15% at the top to 60% at the bottom. I then moved the blend midpoint about a third of the way up from the bottom.
I did the same to the green question mark, and voila!
![]()
I'm really happy with the result. I used the same technique for the shiny tabs and sign up button on the new site too.
BTW, I used OmniGraffle. It's not really designed for this sort of thing but did the job nicely.
by : Created on Jan. 13, 2008 : Last modified Jan. 13, 2008 : (permalink)
The Cringe Test
Back when I was editing Alibi Phone Network in 2004, I found that cuts that seemed fine to me when I watched them alone would make me cringe when I watched them with a friend. I didn't even need to get feedback from the other viewer; I just got embarrassed at certain points and immediately wanted to start making excuses. I dubbed this approach to testing the "cringe test".
I discovered a couple of days ago that the test is useful for websites too. I was showing a friend Quisition for the first time, and without him saying a word I started thinking to myself "oh no, it's not clear where he has to click" or "it's not obvious what that means; I should have explained that better".
by : Created on Jan. 11, 2008 : Last modified Jan. 11, 2008 : (permalink)
Some Goals for 2008
- produce first feature film — In the Light of Day
- dramatically increase the number of Quisition users (more on this soon)
- launch habitualist and at least one other site (one of which is in the works right now)
- make substantial progress on my PhD
- start releasing some of the long-running MorphGNT work I've been collaborating with Ulrik Sandborg-Petersen on
- get at least two of my django-related open source software projects to a 1.0 release
- some other stuff I can't say yet :-)
by : Created on Jan. 10, 2008 : Last modified Jan. 11, 2008 : (permalink)
2007 in Review
At the start of the year, I launched Quisition, my flashcard site. By the end of the year, I had reached my goal of 1,000 users. I've already added a bunch of new features in the new year with lots more to come.
One Friday evening in February, I conceived of, implemented and launched Cats or Dogs. It rapidly took off in the Python community and by PyCon two weeks later, I was being stopped in the hallways and asked if I was the "Cats or Dogs" guy.
Also at PyCon, I chaired a session, participated in the panel on web frameworks and volunteered to be the organizational admin for the Python Software Foundation's participation in the Google Summer of Code. As well as administering, I ended up mentoring two projects over the summer.
In April, I started playing Lord of the Rings Online. The last few months I've probably online averaged no more than an hour per week, but at the peak I was playing a lot. Although I never got around to blogging it, my main character reached level 50 (the current limit).
In May, I got an apartment in the US and said goodbye to long-term hotel stay.
One of my songs, You, Me, Us We had some success, coming in the top 20 in a songwriting content and later being named top song of 2007 by ElectroQueer.
In June, I bought an iPhone. I take it for granted now.
In July, I conceived, implemented and launched PotterPredictions which had a reasonable amount of success in its naturally short life (I still wish I'd thought of it earlier).
In terms of open source, it was a fairly slow year although I did make a lot of progress on django-atompub and pretty much finished support for the syndication format RFC.
I started work on yet another django-based website called habitualist that will hopefully have a closed beta in the next month or so.
In November, I bought a Mini Cooper S and resumed pre-production work on my first feature film.
Finally in December, just before leaving to the UK and Spain for the holidays, I received both an OLPC XO laptop and a 23andMe DNA test kit. More about those later!
They were the 2007 highlights from my blog. A number of other exciting things happened that didn't get blogged about at the time. mValent had a great year and an amazing last quarter; Ulrik Sanborg-Petersen and I made slow but significant progress on a number of MorphGNT projects, the fruits of which should be available soon; Facebook became, for me, both a great way of reconnecting with old friends and a promising platform for development. I made some progress on my PhD but not as much as I would have liked. I need to change that in 2008.
So all-in-all, it was a pretty awesome year. I'm expecting 2008 to be even better. Watch this space!
by : Created on Jan. 9, 2008 : Last modified Jan. 9, 2008 : (permalink)